Sistemul de fisiere
1. Fisierele
__________ ______ ____ __________ ______ ____ _______
Fiecare
fisier este o colectie de date memorata pe un dispozitiv.
Sistemul de gestiune a fisierelor implementeaza aceasta abstractizare
si ofera un tip special de fisier denumit director pentru a organiza structura de fisiere.
De asemenea, acesta ofera o gama de comenzi pentru a manipula
directoarele, a stabili pozitia de scriere/citire in cadrul unui fisier,
a seta mecanismele de protectie ale fisierelor, lista fisierelor
dintr-un director, a sterge un fisier etc.
Marea majoritate a
programelor de aplicatie citesc informatia din unul sau mai multe fisiere,
proceseaza datele si apoi scriu rezultatul intr-unul sau mai multe
fisiere. De exemplu, un program de gestiune a conturilor citeste un fesier
de facturi si un altul de comenzi, coreleaza datele, apoi verifica
si scrie rezultatele intr-un fisier. Un compilator citeste
programul sursa, translateaza programul in cod masina, apoi
scrie un fisier obiect si eventual un fisier de erori. Un
program de optimizare citeste descrierea spatiului ce urmeaza a
fi analizat dintr-un fisier, cerceteaza spatiul pentru minimul/maximul global si scrie
rezultatul intr-un fisier de iesire.
Acest model poate fi usor generalizat. De exemplu, in sistemul
UNIX, cand este creat un proces, el are acces automat la trei fisiere:
- stdin
- ca o abstractizare
a dispozitivului de intrare
- stdout
- ca o abstractizare
a dispozitivului de iesire
- stderr
- ca un fisier
de erori
In
sistemele UNIX stdin, stdout si stderr sunt folosite ca dispozitive de
comunicare mai mult decat de stocare, cu toate ca dispozitivele corespondente
sunt referite folosind fisiere. Concluzia care se desprinde din cele
prezentate este ca programele sunt simple mijloace de definire a filtrelor
care citesc un fisier, transforma datele in altceva, apoi scriu
rezultatul intr-un fisier. Un fisier este un container pentru o colectie
de informatii. Sistemul de gestiune al fisierelor ofera un mecanism
de protectie care permite utilizatorilor sa administreze felul in
care acestia au acces la fisiere. Protectia este o proprietate
fundamentala a fisierelor deoarece permite utilizatorilor sa-si
stocheze informatia pe un calculator partajat cu incredere ca aceasta
va ramane confidentiala.
Stocarea informatiilor pe
termen lung trebuie sa indeplineasca trei conditii:
- Sa fie posibila stocarea
unei mari cantitati de informatie.
- Informatia nu trebuie sa se piarda
dupa incheierea procesului care o foloseste.
- Mai multe procese sa aiba
acces la informatie in acelasi timp.
Solutia la aceste trei cerinte este
memorarea informatiei in fisiere. Informatia memorata in fisiere
trebuie sa fie persistenta, adica sa nu fie afectata
de crearea sau terminarea procesului care o utilizeaza. Componenta din
cadrul sistemului de operare care se ocupa cu gestionarea tuturor operatiilor
legate de fisiere (accesul la fisiere si organizarea acestora pe
disc) poarta denumirea de sistem de fisiere.
Principalele probleme care privesc
modul in care utilizatorii lucreaza cu fisierele: numirea lor, structura, tipurile de
fisiere, modalitatile
de acces si operatiile cu
fisiere.
Numele fisierelor
Fisierul reprezinta
un mod de a memora informatia pe disc pentru a fi utilizata ulterior.
Una
dintre cele mai importante caracteristici ale mecanismului de abstractizare a fisierelor
este modalitatea de identificare a lor. Regulile de denumire a fisierelor difera
de la un sistem de operare la altul. Fiecare sistem de operare are propriul set
de caractere permise pentru denumirea fisierelor, propriile reguli de
formare a numelor fisierelor. De exemplu, in MS-DOS numele au maxim 8
caractere urmate optional de caracterul "." si de o extensie
formata din cel mult 3 caractere. Sistemul MS-DOS nu face deosebirea intre
literele mici si literele mari. Fisierul "sisteme.doc" va fi acelasi cu "Sisteme.doc".
Spre
deosebire de MS-DOS, UNIX-ul face deosebirea intre litere mici si mari,
astfel incat "sisteme.doc" si "Sisteme.doc" vor fi doua fisiere
distincte. Numele fisierelor in UNIX pot avea pana la 255 de
caractere, iar dimensiunea extensiei este arbitrara. In plus, un fisier
poate avea mai multe extensii, cum ar fi exemplul urmator: "diploma.tar.gz".
De
regula, extensia fisierului este utilizata cu scopul de a indica
semnificatia continutului informational al fisierului. In
tabelul 1 sunt prezentate cateva extensii si semnificatia lor.
Tabelul 1. Extensii ale fisierelor
|
Extensie
|
Semnificatie
|
|
.txt
|
Fisierul
contine text
|
|
.doc
|
Document
Word
|
|
.c
|
Program
sursa in limbajul C
|
|
.pas
|
Program
sursa in limbajul Pascal
|
|
.jpg
|
Imagine
grafica
|
|
.bmp
|
Imagine
grafica
|
|
.zip
|
Fisier
comprimat
|
|
.html
|
Pagina
WEB
|
Structura fisierelor
Exista mai multe modalitati
de structurare a fisierelor. Cea mai simpla modalitate de structurare
este de fapt lipsa oricarei structuri. Fisierul este pur si
simplu un sir de octeti. Sistemul de operare nu stie semnificatia
informatiilor din fisier si il priveste pe acesta ca o insusire
de octeti. Aceasta abordare este prezenta la sistemele MS-DOS,
UNIX si WINDOWS 95 si furnizeaza maximul de flexibilitate.
Interpretarea datelor din fisiere este lasata in sarcina
programelor de aplicatie.
A doua
modalitate este de a privi fisierul ca fiind alcatuit dintr-o colectie
de inregistrari de dimensiune fixa. In acest caz operatiile de
citire sau de scriere au loc la nivelul unei inregistrari. In prezent
aceasta metoda de organizare nu se mai foloseste.
Al
treilea tip de structurare al fisierelor consta intr-un arbore de inregistrari,
fiecare continand un camp cheie pe baza caruia se poate
identifica inregistrarea. Arborele este memorat in ordinea cheilor pentru a
permite cautarea rapida a unei chei.
Tipuri de fisiere
Fiecare
sistem de operare suporta un anumit numar de tipuri de fisiere.
Spre exemplu, sistemul UNIX suporta fisiere obisnuite care contin
datele utilizatorilor, fisiere de tip director cu ajutorul carora se organizeaza
sistemul de fisiere pe disc, fisiere speciale asociate
dispozitivelor speciale si fisiere conducta (pipe)
utilizate la comunicarea intre doua procese.
Fisierele
obisnuite pot fi fisiere ASCII sau binare. Fisierele ASCII contin
text care poate fi editat cu ajutorul unui simplu editor de texte si pot
fi afisate/tiparite foarte usor. De asemenea, daca programele
utilizate ca intrare si iesire fisierele ASCII ele pot fi foarte
usor asamblate astfel incat iesirea unui program sa fie
redirectata catre intrarea altui program. Fisierele binare contin
informatii precum programe executabile, imagini grafice. Aceste fisiere
au o anumita structura interna.
Modalitati
de acces la fisiere
Sistemele
de operare mai vechi furnizau o singura modalitate de acces la fisiere: accesul secvential. Pentru a citi
informatii de undeva de la mijlocul fisierului trebuia citit tot fisierul
pana in punctul respectiv. Aceasta modalitate de acces a fost foarte
buna pentru fisierele memorate pe banda magnetica. Odata
cu aparitia discurilor magnetice este posibil sa accesam direct informatia
din orice punct al fisierului. Acest tip de fisiere la care putem
accesa octetii in orice ordine, au acces
aleator. Pentru fisierele cu acces aleator, inaintea unei operatii
de citire/scriere trebuie sa fie indicata pozitia in care va
avea loc aceasta operatie. Indicarea pozitiei se face de obicei
prin invocarea apelului sistem seek.
Atributele fisierelor
Sistemul
de operare asociaza fiecarui fisier un set de informatii,
cum ar fi data si ora la care a fost creat fisierul, proprietarul fisierului
etc. Toate aceste informatii aditionale poarta numele de atributele fisierului. In tabelul 2
sunt prezentate o serie de atribute ale fisierelor.
Tabelul 2. Atributele fisierelor
|
Atributul
|
Semnificatia
|
|
Proprietar
|
Identificatorul
proprietarului fisierului
|
|
Parola
|
Parola de acces la
fisier
|
|
Read-only
|
Fisierul poate fi doar
citit
|
|
Hidden
|
Fisier ascuns
|
|
System
|
Fisier ce apartine
sistemului de operare
|
|
Timpul ultimului acces
|
Data si ora cand a fost
accesat ultima oara
|
|
Timpul ultimei
modificari
|
Data si ora cand a fost
ultima oara modificat
|
|
Dimensiune
|
Marimea fisierului
in bytes
|
Operatii cu fisierele
- Creare. Se creeaza fisierul,
fara a memora date.
- Stergere. Cand nu mai este
nevoie de fisier, el este sters pentru a elibera spatiul pe
disc.
- Redenumire. Se schimba
numele fisierului la cererea utilizatorului.
- Descriere. Inainte de
utilizarea unui fisier acesta trebuie deschis pentru a permite
sistemului de operare sa aduca in memoria principala lista
cu blocurile de pe disc unde se afla stocat fisierul.
- Inchidere. Operatia de
inchidere a unui fisier elibereaza toate resursele alocate de
sistemul de operare pentru lucrul cu fisierul respectiv (tabele
interne).
- Scriere/citire. Se scriu/citesc
date in/din fisier la o anumita pozitie specifica fata
de inceputul fisierului.
- Pozitionare. Se indica pozitia
unde va avea loc urmatoarea operatie de scriere/citire.
- Obtinerea/Setarea
atributelor. Cu ajutorul acestor operatii se pot citi sau
modifica atributele fisierelor.
2. Directoarele
__________ ______ ____ __________ ______ ____ _______
Pentru a organiza fisierele
pe disc se utilizeaza de regula directoarele. Acestea sunt la randul
lor tot fisiere, dar cu o structura mai speciala. Un director
este alcatuit sub forma unui tabel in care pe fiecare linie sunt scrise
datele referitoare la un fisier: numele, atributele si un indicator catre
o structura de date care mentine o lista cu blocurile de disc
unde sunt memorate datele din fisier. Aceasta organizare a
directoarelor poate fi urmarita in figura 1.
|
oois97.zip
|
atribute
|
|
|
ideas99.pdf
|
atribute
|
|
|
techguide.tgz
|
atribute
|
|
|
ucb-ms.ps
|
atribute
|
|
Structuri de date ce
mentin o
lista cu blocurile fisierelor
Figura 1. Structura unui director
Numarul de directoare depinde de tipul sistemului de
operare.
Cea mai avansata metoda de organizare a
sistemului de fisiere este aceea a unei ierarhii de directoare, acestea
alcatuind o structura arborescenta. De regula, aceasta
structura arborescenta porneste dintr-un nod denumit director radacina.
Pentru identificarea fisierelor intr-o astfel de
structura arborescenta avem la dispozitie doua metode. O
prima metoda este utilizarea unei cai absolute. De exemplu,
"/home/bogdan/working/carte.tex" reprezinta calea absoluta de acces la
fisierul "carte.tex". Prin primul simbol " " am marcat directorul radacina, iar
urmatoarele simboluri " " au doar rolul de a desparti numele de
directoare.
In orice moment un proces are un director curent de lucru. Daca spre exemplu, directorul curent
de lucru este "home", atunci
fisierul "carte.tex" poate fi specificat in felul urmator: "bogdan/.working/carte.tex". Se observa ca in acest caz calea de acces
porneste din directorul curent fara a mai fi nevoie de
parcurgerea intregului arbore incepand cu radacina. Calea
construita in acest fel se numeste cale relativa.
Majoritatea sistemelor de operare care ofera
utilizatorilor un sistem de fisiere organizat ierarhic arborescent are
doua intrari speciale in fiecare director: " si " ". directorul " " simbolizeaza
in orice moment directorul curent, iar " "
simbolizeaza directorul parinte.
De exemplu, sa presupunem ca directorul curent de lucru este "/home/bogdan/working". Pentru a copia fisierul "server.class" din directorul "/home/bogdan" in directorul "/home/bogdan/working" se poate folosi comanda UNIX: cp../server.class .
" " indica faptul ca "server.class" se
afla in directorul parinte al directorului curent, iar " " indica faptul
ca fisierul "server.class" va fi
copiat in directorul curent.
Operatii cu directoare
Operatiile permise asupra directoarelor variaza
de la un tip de sistem de operare la altul. In continuare sunt prezentate o
serie de operatii de lucru directoare in sistemul UNIX:
Creare. Se creeaza un director nou care este gol. El contine
totusi inca de la creare cele doua intrari speciale " si " "
Stergere. Un director poate fi sters doar daca este gol.
Daca acesta contine fisiere, mai intai trebuie sterse
fisierele, apoi se va putea sterge directorul.
Deschidere. Inainte de a fi citit, directorul trebuie deschis ca orice alt
fisier.
Inchidere. Dupa ce a fost citit, directorul va fi inchis,
eliberandu-se astfel resursele alocate de sistem pentru lucrul cu directorul
respectiv.
Citirea. Operatia de citire a unui director va returna numele
tuturor fisierelor pe care acel director le contine.
Redenumirea. Aceasta este operatia de schimbare a numelui unui director.
Efectuarea de legaturi (link). O legatura permite ca un
fisier sa apara in mai multe directoare. Fisierul nu este
copiat fizic in fiecare director, ci este creata o intrare in tabele
directoarelor in care dorim sa apara fisierul. Din punct de
vedere fizic, fisierul este memorat o singura data, intr-un
singur director.
Stergerea unei legaturi (unlink). Prin stergerea unei
legaturi se indeparteaza de fapt o intrare in tabela
directorului. Daca fisierul a carui intrare a fost
indepartata mai apare si in alt director, atunci el
continua sa existe in sistemul de fisiere si poate fi
utilizat. Doar cand a fost stearsa si ultima legatura
a unui fisier atunci el este sters fizic de pe disc.
3. Implementarea sistemului de fisiere
__________ ______ ____ __________ ______ ____ _______
Cea mai importanta problema
in implementarea sistemului de fisiere este modul cum va fi mentinuta
lista blocurilor de disc unde se afla memorate datele unui fisier.
O metoda foarte simpla de
alocare este aceea de a atribui un sir continuu de blocuri pentru un
fisier. De exemplu, daca dimensiunea blocului de pe hard disc este de
1KB, iar dimensiunea unui fisier este de 30KB, atunci pentru acest
fisier vor fi alocate 30 de blocuri consecutive. Aceasta metoda
are avantajul simplitatii, deoarece pentru un fisier trebuie
mentinuta doar adresa primului bloc si dimensiunea fisierului,
dar si al performantei - fisierul fiind alocat in blocuri
consecutive poate fi citit printr-o singura operatie.
Totusi, in practica,
aceasta metoda nu se utilizeaza aproape deloc deoarece
prezinta dezavantaje majore. Daca dimensiunea fisierului nu este
cunoscuta de la inceput, sistemul de operare nu va putea sti cat
spatiu sa aloce pentru fisier. Pe parcursul utilizarii este
posibil ca dimensiunea acestuia sa creasca. In aceasta
situatie, daca la sfarsitul fisierului nu mai exista
spatiu liber pentru alocare de noi blocuri pentru fisier, atunci sistemul
de operare va trebui sa-l stearga si sa caute un alt
spatiu liber pe disc in care sa poata fi alocat fisierul.
Pe langa faptul ca stergerea si realocarea consuma
mult timp, dupa o anumita perioada discul va fi fragmentat. Se
va ajunge la situatia in care pe disc exista mult spatiu liber,
dar care nu poate fi utilizat din cauza numarului mic de blocuri continue
care sunt libere.
O alta metoda de memorare a
fisierelor pe disc este de a mentine o lista
inlantuita cu blocurile alocate unui fisier. Fiecare bloc
are un pointer catre urmatorul bloc alocat unui fisier si o
zona de date utile. Prin aceasta metoda se evita problemele
care apareau la alocarea continua deoarece toate blocurile de pe disc
pot fi alocate. In director, se va memora pentru fiecare fisier in parte
adresa primului bloc de disc unde se afla datele. Apoi, prin parcurgerea
listei vor putea fi accesate toate blocurile fisierului. Desi
parcurgerea secventiala a fisierului este simpla (se
parcurge secvential lista inlantuita de blocuri), la accesul
aleator apar probleme (lista simplu inlantuita poate fi
parcursa intr-un singur sens). Pentru a evita aceste probleme se poate
utiliza o lista dublu inlantuita care permite parcurgerea
in ambele sensuri. Chiar si cu liste dublu inlantuite, accesarea
unui fisier este mare consumatoare de timp deoarece parcurgerea listei de
blocuri implica operatii cu discul care sunt foarte lente.
O metoda care elimina
dezavantajul parcurgerii listei de blocuri pe disc consta in construirea
unei tabele in memoria principala, tabela ce va memora adresele blocurilor
ce apartin unui fisier.
|
|
3
|
4
|
8
|
|
|
|
9
|
12
|
|
|
EOF
|
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
|
Figura 2. Tabela de alocare a fisierelor
In figura 2 este prezentat un exemplu
de astfel de tabela. O intrare in tabela va memora adresa urmatorului bloc
ce apartine unui fisier. Fisierul considerat in exemplul din
figura 8.2 este alocat pe disc in blocurile cu numerele 2, 3, 4, 8, 9 si
12. Blocul 2 va memora cifra 3, adica adresa urmatorului bloc ce
apartine fisierului, blocul 3 va memora cifra 4, blocul 4 va memora
cifra 8 s.a.m.d. Ultimul bloc contine o valoare speciala care
indica sfarsitul fisierului. Aceasta metoda este
utilizata de sistemul MS-DOS. Dezavantajul major il constituie faptul
ca tabela trebuie mentinuta in memorie, ceea ce implica un
necesar mare de memorie pentru sistemul de operare.
Sistemul UNIX utilizeaza o
metoda mai complicata, dar in acelasi timp mai eficienta de
memorare a blocurilor ce apartin unui fisier. Fiecare fisier are
asociata o mica tabela denumita i-node. In i-node sunt memorate mai intai
atributele fisierelor, apoi o lista cu blocurile ce apartin
fisierului. Primele cateva blocuri sunt memorate chiar in i-node, astfel incat pentru
fisierele de dimensiune mica acestea sunt suficiente. Pentru
fisierele de dimensiune mai mare exista o intrare in i-node ce puncteaza catre un
bloc de disc denumit bloc de indirectare simpla.
Acesta contine adresele altor blocuri de disc ce apartin
fisierului. Daca nici aceste blocuri nu sunt suficiente, in i-node mai exista o intrare ce
puncteaza catre un bloc de pe disc denumit bloc de indirectare dubla. Acesta contine adresele unor
blocuri de indirectare simpla care la randul lor puncteaza catre
blocuri de pe disc ce apartin fisierului. Daca nici aceste
blocuri nu sunt suficiente, in i-node
se mai gaseste o intrare ce puncteaza catre un bloc
cu indirectare tripla.
Atunci cand un utilizator
acceseaza un fisier, sistemul de operare trebuie sa stie
unde se afla plasate blocurile de disc ce apartin acelui fisier.
Acest lucru il afla din directorul unde se afla directorul respectiv.
4. Sistemul de
fisiere virtual
__________ ______ ____ __________ ______ ____ _______
Anumite sisteme de operare, cum este,
de exemplu, Linux, o varianta de UNIX, pot lucra cu mai multe sisteme de
fisiere: FAT (de la MS-DOS), FAT32 (Windows98), NTFS (de la Windows NT
si 2000), ext3 (sistemul nativ al Linux-ului) etc. Acest lucru este posibil
prin introducerea conceptului de sistem de fisiere virtual.
Managerul de fisiere este
construit pe un model de fisiere abstract care este exportat de componenta
VFS (Virtual File System). VFS
implementeaza operatiile independente ale sistemului de fisiere.
Proiectantii sistemului de operare asigura extensii ale VFS pentru a
implementa toate operatiile dependente de un sistem de fisiere
particular; versiunea 2.x a VFS poate citi si scrie fisiere de pe
disc care se conformeaza formatului MS-DOS, formatului MINIX, formatului /proc,
formatului specific Linux denumit Ext3 si altele. Bineinteles
aceasta inseamna ca anumite componente dependente ale sistemului de
fisiere sunt incluse in versiunea 2.x pentru a traduce operatiile
si formatele VFS in/din fiecare dintre formatele externe care sunt
suportate.
"Inima" VFS-ului este comutatorul (switch), care
asigura managementul de fisiere recunoscut interfata cu
programele din spatiul utilizator (API) si care, de asemenea, stabileste
o interfata interna folosita de diferite translatoare al
sistemului de fisiere care suporta fisiere MS-DOS, fisiere
MINIX, fisiere ext3 etc. (vezi
figura 4).
Un nou sistem de fisiere poate fi
suportat prin implementarea unei noi componente dependente ("translator") a sistemului de fisiere. Fiecare astfel de
translator asigura functii pe care comutatorul VFS il poate apela
(cand este apelat de un program utilizator), si care poate translata
reprezentarea externa a fisierului intr-una interna.
Astfel, translatorul este responsabil
de determinarea strategiei utilizate pentru a organiza blocurile pe dispozitivul
discului, de citirea si scrierea proprietatilor discului, de citirea
si scrierea informatiei, descriptorului fisierului extern,
si de citirea si scrierea blocurilor de disc care contin datele
fisierului.
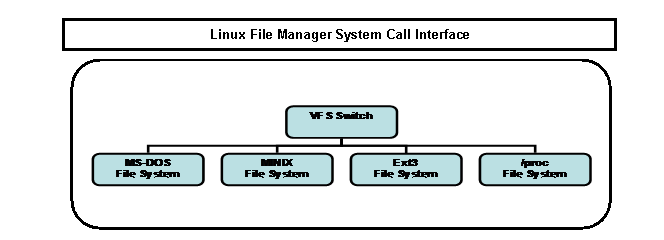
Figura 4. Comutatorul
VFS
Modelul sistemului de fisiere VFS este aplicat
dupa sistemele de fisiere conventionale UNIX. Un descriptor de fisier VFS este denumit v-node
(desi acesta are propriul sau format unic care suporta abordarea
sistemului de fisiere multiplu). Desi VFS va contine propriul
sau format pentru un descriptor de fisier, fiecare translator
dependent de sistemul de fisiere extern converteste
continuturile descriptorului extern in formatul VFS v-node cand este deschis
fisierul. Deci VFS
opereaza asupra propriei sale structuri de date v-node. Dimpotriva,
cand fisierul este inchis, continuturile v-node-ului intern sunt utilizate pentru a
actualiza descriptorul de fisier extern.
V-node-ul VFS contine drepturile de acces ale
fisierului proprietarul, grupul, marimea, data crearii, ultima
data cand a fost accesat, ultima data cand fisierul a fost scris etc.
De asemenea, v-node-ul
rezerva spatiu pentru mecanismul de pointeri pe care sistemul de
fisiere specific il foloseste pentru a organiza blocurile de disc,
chiar daca VFS nu stie cum
vor fi organizati acesti pointeri (aceasta informatie este
incapsulata in componenta translatorului specifica sistemului de
fisiere). VFS suporta, de
asemenea, directoare, deci se presupune ca directoarele fisierelor
externe contin cel putin numele fiecarui fisier stocat in director,
si adresa descriptorului sau de fisier (aproape toate sistemele
de fisiere contin aceasta minima cantitate de informatie).
VFS presupune o structura minima a
organizarii discului:
Primul
sector de pe disc este un bloc de biot (boot block) folosit pentru a stoca
un program de incarcare a sistemului de operare. Sistemul de fisiere
nu foloseste in realitate blocul de boot, dar se presupune ca este prezent in fiecare
sistem de fisiere.
Exista
un superblock,
continand informatii specifice discului, cum ar fi numarul de octeti
intr-un bloc de disc.
Exista
descriptori de fisiere externe
pe disc care descriu caracteristicile fiecarui fisier.
Exista
blocuri de date care sunt legate in
fiecare fisier pentru a contine datele.
Inainte ca VFS
sa poata lucra cu un tip particular de sistem de fisiere,
trebuie sa fie scris un translator pentru acel tip si apoi
inregistrat in VFS. Functia VFS
register_filesystem(
) informeaza VFS despre
informatiile de baza de care va avea nevoie, inclusiv numele tipului
de sistem de fisiere si punctul de intrare al functiei read_super(
) a sistemului de fisiere care va fi utilizata cand sistemul
de fisiere este montat.
Sistemul de
fisiere la Windows
__________ ______ ____ __________ ______ ____ _______
Unitati individuale de hard-discuri pot
fi divizate in partitii care sunt subdivizii logice ale hard-discului.
Fiecare hard-disk poate avea pana la 4 partitii, desi numai una
este desemnata ca partitie activa. O partitie poate fi
primara sau extinsa. Partitiile extinse sunt formate din
unitati logice care apar ca litere distincte de unitati de
hard-disc in sistemul de operare. Un hard-disc poate avea o singura
partitie extinsa.
De obicei, hard-discurile sunt configurate cu o partitie primara si o
partitie extinsa care este formata din mai multe
unitati logice.
Presupunand ca se doreste
impartirea unui hard-disc in 4 pozitii, apoi instalarea sistemului pe una dintre ele, se procedeaza astfel:
se creeaza o partitie primara pe care se va instala Windows
avand dimensiunea necesara, apoi pentru restul discului se creeaza o
partitie extinsa in care se vor crea 3 unitati logice.
Partitionarea in Windows este facuta
cu ajutorul unui program utilitar numit FDISK
(Fixed Drive Setup Program). FDISK
permite vizualizarea partitiilor existente si permite stergerea
si crearea partitiilor.
Datele despre partitiile unei
unitati de hard-disk sunt salvate ca parte a MBR (Master Boot Record) care se afla la cilindrul 0, capul 0,
sectorul 1. O sectiune de 64 bytes din MBR contine configurarea partitionarii
unitatii de hard-disc. Fiecare partitie este definita ca o
intrare de 16 bytes (ceea ce inseamna ca nu pot fi mai mult de 4
partitii 4*16=64).
Inauntrul sectorului MBR, datele despre partitii incep de la offset-ul 446 si
ocupa 512 bytes (ultimii 2 bytes nu sunt utilizati, ei marcand
sfarsitul sectorului si vor avea - intotdeauna valoarea 0x55AA).
Fiecare intrare in tabela de partitii este
aranjata dupa cum urmeaza:
Byte-ul
00 retine indicatorul de boot care poate fi 0x00 sau 0x80. 0x80
indica faptul ca partitia este utilizata pentru
operatia de "boot" a unui sistem de
operare; 0x00 indica faptul ca partitia nu este utilizata
pentru "bootare".
Byte-ul
01 retine numarul capului de inceput al partitiei.
Byte-ul
02 si 03 retin o intrare combinata care localizeaza
sectorul si cilindrul de inceput al partitiei, primii 6 biti
retin sectorul iar urmatorii 10 cilindrul.
Byte-ul
04 retine ID-ul sistemului. ID-ul sistemului indica sistemul de
fisiere folosit de partitie si este setat de comanda FORMAT cand
partitia este formatata cu un anumit sistem de fisiere (FAT , FAT32, NTFS etc.).
Byte-ul
05 retine capul de sfarsit.
Byte-ul
06 si 07 sunt o alta intrare combinata retinand sectorul
si cilindrul de sfarsit al partitiei. Primii 6 biti
retin sectorul, iar urmatorii 10 retin cilindrul.
Byte-ul
8 pana la 11 retin sectorul relativ, care este numarul relativ
al sectorului de la care incepe partitia.
Byte-ul
12 pana la 15 retin numarul de sectoare din interiorul
partitiei.
Unitatile logice isi
pastreaza datele despre partitie intr-un alt fel decat
partitia primara sau partitia extinsa. Ceea ce se
intampla in realitate este astfel: o intrare in MBR a unei partitii extinse indica primul sau
sector, care este locatia primei unitati logice din
partitia extinsa. Primul sector al unitatii logice stocheaza
o alta tabela de partitie. Tabela de partitie a unitatii logice este stocata
in ultimii 64 bytes al primului sector aranjati exact ca tabela din MBR. Oricum, tabela de partitie a
unitatii logice, contine doar 2 intrari: prima intrare
contine configuratia unitatii logice iar urmatoarea
intrare contine configuratia urmatoarei unitati
logice. Intrarile 3 si 4 sunt goale si nu sunt folosite. A doua
intrare puncteaza catre urmatoarea unitate logica care la
randul ei contine tabela de partitii si asa mai departe.
FAT (File Alocation Table) - tabela de
alocare a fisierelor
Orice sistem de operare se bazeaza pe unul sau
mai multe sisteme de fisiere, care sunt modelele folosite pentru a memora
fisierele pe unitati de stocare. Exista multe sisteme de
fisiere ca, de exemplu, FAT, NTFS
(New Techonology File System), HPFS (Hight
Performance System), CDFS (CD-ROM
File System) si asa mai departe. Windows 98 poate utiliza 4 sisteme
de fisiere: FAT 16, FAT3 CDFS
si UFS (Universal File System ) pentru unitati de DVD-ROM.
FAT
(File Allocation Table)
este o metoda pentru a stoca fisiere si directoare pe hard-disk.
FAT are o lunga istorie, fiind pentru prima data utilizat sub MS-DOS.
Un volum formatat FAT este
aranjat incepand cu o partitie primara urmata de doua copii
identice ale FAT-ului (FAT1,
FAT2), listingul directorului radacina restul discului. Cele
doua copii ale FAT-ului sunt
necesare pentru a preintampina distrugerile.
Sectorul de boot
al partitiei contine informatii necesare bootarii
sistemului de operare (daca partitia primara are acest scop).
Datele din sectorul de boot al partitiei sunt redate in tabelul
urmator:
|
Bytes
|
Descriere
|
|
3
|
Instructiune de salt
|
|
8
|
Numele sistemului de
operare OEM
|
|
25
|
BIOS Parameter Block
|
|
26
|
Extended BIOS Parameter
Block
|
|
448
|
Bootstrap code
|
Blocurile de parametri BIOS (ambele, normal si extins) stocheaza informatii
suplimentare despre volume, cum ar fi numarul de bytes pe sector, numarul
de sectoare pe cluster, numarul de intrari in directorul
radacina si altele.
Volumele FAT sunt divizate in
unitati de alocare, numite cluster.
FAT16 poate memora numerele
clusterelor pe 16 biti (in numar de 65536), in timp ce FAT32 le memoreaza pe 32 biti
(4.294.967.296.). In functie de lungimea discului clusterele pot avea
lungimi diferite. Dimensiunea minima a unui cluster este 512 bytes,
dimensiunile mai mari sunt multiplu de 2 (de exemplu 1024, 2048, 4096 etc).
Dimensiunea maxima sub FAT este
de 65536 (64 KB).
Fiecare fisier de pe disc consuma cel
putin un cluster. Pe un volum cu clustere pe 32 KB un fisier de 1
byte consuma 32 KB spatiu pe disc. Daca un fisier de pe
acelasi disc are 32 KB + 1byte el va ocupa doua clustere, deci 64KB.
Volumele de FAT16
nu pot avea mai mult de 4 GB, pentru ca 65536 clustere cu cate 65536 bytes
pentru fiecare inseamna 4 GB. Tabelul urmator prezinta
marimile maxime ale volumelor si marimile corespunzatoare ale
clusterelor:
|
Marimea
volumului
|
Marimea
clusterului
|
|
32 MB
|
512 bytes
|
|
64 MB
|
1
KB
|
|
128 MB
|
2 KB
|
|
255 MB
|
4 KB
|
|
511 MB
|
8 KB
|
|
1023 MB
|
16 KB
|
|
2047 MB
|
32 KB
|
|
4095 MB
|
64 KB
|
Tabela FAT este o simpla lista
inlantuita. Fiecare intrare de fisier puncteaza
catre primul cluster folosit.
Sa luam urmatorul exemplu: un
fisier are lungimea de 70 KB si lungimea unui cluster este de 32 KB.
Intrarea fisierului in director spune ca primul cluster este
numarul 234 Sistemul de operare gaseste apoi toate
partile fisierului citind intai intrarea FAT 2345 (pentru primii 32 KB ai fisierului). Intrarea FAT indica ca urmatorul
cluster este, sa spunem, 4123 (pentru urmatorii 32 KB). Clusterul
4123 spune ca urmatorul numar este 932 (ultimii 8 KB ai
fisierului). Intrarea FAT a
clusterului 932 stocheaza 0xFFFF in loc de un pointer la urmatorul
cluster, indicand astfel ca ultimul cluster al fisierului a fost
atins.
Fiecare intrare FAT corespunde unui cluster si contine informatie
relativ simpla:
Daca clusterul este folosit sau nu.
Daca clusterul este marcat ca fiind
stricat sau nu.
Un pointer (o intrare de 16 bytes in FAT) punctand catre
urmatoarea legatura din lant sau 0x FFFF indicand ca
este ultimul din lantul unui fisier.
Informatia fisierului este stocata
in zona de date a volumului, exceptand directorul radacina care
este la o pozitie fixa pe un volum FAT 16. Directorul radacina este limitat la 512
intrari in FAT 16.
Fiecare director in FAT 16 este de fapt un fisier, dar un fisier care este
marcat ca director astfel incat sistemul de operare stie sa lucreze
cu el. In interiorul unui fisier de tip director se afla toate
fisierele continute si toate subdirectoarele. Cand se introduce
comanda DIR de fapt se listeaza
continutul fisierului director, formatat astfel incat sa
poata fi usor de citit.
Directoarele consuma clustere la fel ca
si fisierele. Fiecare intrare intr-un director contine
urmatoarele informatii:
Numele
fisierului sau directorului stocat ca 11 bytes (in formatul 8,3 punctul nu
este stocat).
8
biti indicand atributele intrarii.
24
biti indicand timpul cand fisierul a fost creat.
16
biti indicand data la care a fost creat fisierul.
16
biti indicand data cand a fost ultima data accesat fisierul.
16
biti indicand timpul cand a fost modificat ultima data fisierul.
16
biti indicand data cand a fost modificat ultima data fisierul.
16
biti (FAT16) indicand numarul primului cluster ocupat de intrare.
32
biti indicand lungimea intrarii.
Bitii de atribut indica daca o
intrare este pentru un fisier sau pentru un director, daca intrarea
este folosita pentru o eticheta de volum sau nu si atributele
setabile ale utilizatorului (read-only,
hidden, system, archive).
Pentru
a intelege mai bine cele spuse sa urmarim exemplul urmator.
Un fisier numit "test.fil" este stocat in directorul
"c:WindowsSystem", are o lungime
de 50 KB si este citit de o aplicatie. Volumul utilizeaza
clustere pe 32KB.
1.
Aplicatia
cere datele fisierului de la sistem. Aplicatia trimite sistemului de
operare numele si directorul fisierului sub forma unei cai
complete "c:WindowsSystemtest.fil".
2.
Sistemul
de operare localizeaza fisierul scanand mai intai intrarile din
directorul radacina pentru intrarea "Windows" care are atributul setat pe director.
3.
Intrarea
directorului "Windows" indica
faptul ca incepe la clusterul 55 Este apoi citit FAT-ul; utilizand lista inlantuita din FAT sistemul de operare descopera
ca directorul "Windows" ocupa
clusterele 1123, 2342, 523 si 4923. Utilizand aceasta informatie
sistemul de operare citeste directorul "Windows"si il scaneaza pentru o intrare numita "System".
4.
Intrarea
"System" este gasita in
listingul directorului "Windows"
si are atributul setat pe director. Intrarea "System" indica numarul 1154 ca fiind primul cluster al
directorului.
5.
Este
citit FAT-ul din nou incepand de la
clusterul 1154 si urmarind lantul pana cand sunt recunoscute
clusterele directorului "System". Utilizand informatia sistemul de
operare citeste directorul "System" in memorie si il scaneaza
pentru o intrare numita "test.fil".
Intrarea este gasita si atributul sau pentru director este
gasita indicand ca este un fisier. Prin citirea
intrarii sistemul de operare afla ca primul cluster al
fisierului "test.fil" este 2987.
6.
FAT-ul
este citit din nou incepand cu clusterul 2987. Utilizand lista
inlantuita, sistemul de operare localizeaza ambele clustere
care contin fisierul si apoi il citeste aducandu-l -n
memorie.
7.
Sistemul
de operare transfera apoi continutul clusterelor aplicatiei sub
forma unui flux de bytes.
Dupa cum se poate vedea, obtinerea unui
fisier necesita operatii complicate. Din fericire, sistemul
tine majoritatea intrarilor directoarelor si intreaga
tabela FAT in RAM, deci citirea
directoarelor si a intrarilor directoarelor si a intrarilor
FAT nu necesita prea mult
lucrul cu discul. Oricum, trebuie retinut ca scrierea unui
fisier necesita cativa pasi. Bazandu-se pe lungimea
fisierului, sistemul de operare trebuie sa scaneze FAT-ul pentru
clustere libere care pot fi asignate fisierului:
Ambele FAT-uri trebuie sa aiba
lista inlantuita a fisierului care este scris in ele.
Directorul care contine fisierul
trebuie sa aiba intrarea fi[ierului modificata.
In sfarsit, continutul
fisierului este salvat.
FAT32
Incepand cu Windows
OEM Service Release 2 (OSR2)
si continuand cu Windows 98, Microsoft a dezvoltat o versiune
modificata a lui FAT16 numita FAT32. Pentru ca hard-discurile
cresteau foarte rapid, transferul catre FAT32 era cerut pentru a
suporta discuri mai mari fara sa se utilizeze clustere
nerezonabil de mari.
FAT32 lucreaza in mare masura la
fel ca FAT16 si Microsoft a
lucrat pentru a minimiza diferentele, in scopul reducerii
incompatibilitatilor. Totusi, exista cateva deosebiri intre
FAT16 si FAT32.
Fiecare
intrare FAT consuma acum 4 bytes in loc de 2 bytes. Aceasta schimbare
plus faptul ca pot fi mai multe intrari FAT inseamna ca
FAT-ul insusi este mai larg acum.
MBR este expandat de la un sector la doua
sectoare pentru ca un bloc de parametri BIOS este mai larg, precum si
pentru faptul ca exista 2 copii ale MBR-ului prevenind astfel
distrugerile accidentale.
Directorul
radacina nu mai este la o pozitie fixa. Directorul
radacina este acum tratat ca orice alt director si poate fi
plasat oriunde pe volum. Din aceasta cauza numarul
intrarilor in directorul radacina nu mai este limitat la
512.
Intrarile
in directoare nu au fost modificate cu exceptia celor 2 bytes
nefolositi sub MS-DOS si Windows (toate versiunile) care erau la
sfarsitul intrarii si care erau planificati pentru atribute
extinse OS/2. Ei sunt folositi acum ca 16 biti pentru a indexa un
numar complet de 32 biti de clustere.
Marimea
minima a clusterelor sub FAT32 este de 4KB in loc de 512 bytes cat era sub
FAT16.
Toate aceste schimbari, precum si unele
modificari pentru performanta ofera urmatoarele
avantaje fata de FAT16:
O
singura partitie se poate extinde acum pana la 2 TB.
Pentru
partitii largi ca, de exemplu, cele de peste 8GB, marimea clusterelor
este de doar 4KB in loc de 128KB, pe care teoretic FAT16 i-ar fi folosit
daca ar fi fost posibil sa suporte partitii de 8GB. Din
cauza ca marimea clusterelor este mai mica decat sub FAT16,
aproape 15% din spatiul discului se economiseste.
FAT32
este mult mai sigur decat FAT16, riscurile incidentelor fiind reduse prin
pastrarea unei copii redundante a inregistrarii de boot.
Pentru
ca marimea obisnuita a clusterelui sub FAT32 este de 4KB (care
este si marimea paginilor de memorie utilizate de managerul de
memorie virtuala) activitatea de paginare este mult mai rapida
si necesita mai putine operatii.
Aplicatiile
pornesc mai rapid decat in FAT16.
Exista insa si dezavantaje:
FAT32
nu este inca suportat de Windows NT (pana la versiunea 4), deci nu se
poate converti partitia primara daca vrem sa avem boot dual
Windows 98 si Windows NT. Unitatile logice formatate sub FAT32
sunt ignorate de Windows NT 4.
Nu se
poate reconverti o partitie de la FAT32 la FAT16 la fel cum se poate trece
de la FAT16 la FAT32. Pentru a face acest lucru trebuie reformatata
partitia.
Toate
programele utilitare cere mergeau pentru FAT16 nu mai merg sub FAT32, incluzand
editoare de sectoare de disc, programe vechi de defragmentare si toate programele
de compresie.
Daca
se converteste prima partitie sub FAT32 nu se va putea avea acces la
unitate sub MS-DOS.
Numele lungi de fisiere sub FAT
Dupa cum este probabil clar nu exista
spatiu extins pentru a stoca nume de fisiere mai mari de formatul 8.3
suportat de DOS. Si totusi Windows 95, Windows 98, Windows NT
suporta nume lungi pe astfel de volume FAT. Cum este acest lucru posibil?
Intrarile in directoare au numar de
biti pentru atribute, unul indicand daca intrarea este pentru o
eticheta de volum. In primele versiuni de MS-DOS, de obicei era o
singura intrare de acest gen, localizata in directorul
radacina si care indica eticheta de volum a discului.
MS-DOS ignora de regula alte astfel de intrari la fel cum de
altfel si alte programe utilitare le ignora.
Microsoft a dezvoltat o schema prin
intermediul careia poate stoca numele lungi utilizand acest atribut de
eticheta de volum. Cand se creeaza un fisier cu nume lung sub
Windows 98 ca, de exemplu, MZLONGFILE.TXT,
sunt create mai multe intrari in director; incepand cu a doua intrare,
toate au setat atributul de eticheta de volum (deci MS-DOS si alte
programe utilitare pur si simplu le ignora). Windows 98
stocheaza parti din numele lung in aceste intrari pana
la 11 caractere. In acest caz MYLONGFILE.TXT,
va fi stocat in 2 intrari in director: in primul este stocat MYLONG~1.TXT in timp ce cea de-a doua
parte nu este vizibila decat cu un editor de sectoare.
Numele lungi sub Windows 98 se supun
urmatoarelor reguli:
Pot
contine spatii goale.
Partea
scurta din nume poate folosi urmatoarele caractere speciale: $ % `- _
@ ~ ´ ! ( ) ^ # &
Nume
lungi pot utiliza aditional urmatoarele caractere: + , ; [ ] =
Lungimea
maxima a numelui, incluzand si extensia este de 254 caractere.
Lungimea
maxima a unei cai complete sub Windows 98 este de 260 caractere. Cu
alte cuvinte, daca un nume de fisier are 254 caractere, el poate avea
un director asociat lui de maxim 4 caractere lungime.
Daca
se copiaza sau muta fisiere cu nume lungi cu ajutorul unor
utilitare care nu suporta nume lungi, sau daca se copiaza sau
muta astfel de fisiere pe un server de fisiere care nu
suporta nume lungi, numele lungi se vor pierde.
Cand
se folosesc nume lungi ce contin spatii la prompt-ul MS-DOS trebuie
sa fie incadrate intre ghilimele ("").
O
problema care apare la prompt-ul MS-DOS este ca bufferul pentru
comenzi este limitat la maximum 128 caractere. De aceea, la prompt-ul MS-DOS nu
se pot utiliza nume de fisiere care impreuna cu calea
depasesc 128 caractere. Se poate expanda limita maxima a bufferului
cu ajutorul comenzii:
SHELL=C:WINDOWSCOMMAND.COM/U:255
in fisierul CONFIG.SYS
(255 este valoarea maxima absoluta admisa).
NTFS - New Technology File System
Desi NTFS nu este suportat de Windows 98, o
discutie despre sistemele de fisiere Windows nu este completa
daca nu ar include si detalii despre NTFS.
New Technology File System (NTFS) a fost proiectat
pentru a fi un sistem de fisiere adecvat utilizarii pe servere de
fisiere sau sisteme de inalta performanta. NTFS include
urmatoarele facilitati:
Este orientat pe tranzactii, iar
esecurile de a completa o tranzactie de disc poate fi rezolvata
in timpul verificarii cu programul CHKDSK.
Suporta
"hot-fixing", ceea ce inseamna
ca sectoarele defecte sunt marcate in timpul functionarii.
Ofera
suport complet pentru nume lungi de fisiere.
Retine
timpul la care s-a facut ultimul acces (FAT-ul retinea numai data).
Volumele
si fisierele sub NTFS pot ocupa pana la 264 bytes.
Utilizeaza
o tabela de fisiere bazata pe un arbore binar, ceea ce face ca
regasirile sa fie mult mai rapide decat sunt in FAT.
NTFS
stocheaza clusterele mult mai eficient decat o face FAT; sistemul de
fisiere lucreaza mult mai mult pentru a evita fragmentarea. Din cauza
faptului ca NTFS utilizeaza un arbore binar de cautare a
clusterelor, fragmentarea cauzeaza mai pu3ina degradare a
performantelor decat cea din FAT.
Spre deosebire de High Performance System (HPFS proiectat pentru OS/2), NTFS
utilizeaza lungimi de clustere diferite, similar FAT-ului. Totusi
marimea clusterelor sub NTFS este mult mai mica decat sub FAT16
dupa cum urmeaza:
|
Marimea
partitiei
|
Marimea
clusterului
|
|
512 MB
|
512 bytes
|
|
1024 MB
|
1 KB
|
|
2048 MB
|
2 KB
|
|
4096 MB
|
4 KB
|
|
8192 MB
|
8 KB
|
|
16384 MB
|
16 KB
|
|
32768 MB
|
32 KB
|
|
>32768 MB
|
64 KB
|
Volumele NTFS sunt organizate dupa cum
urmeaza:
Sectorul de boot al partitiei
Master File table
NTFS System File
Zona de fisiere
Zona Master
File Table si NTFS System File
sunt de fapt aceeasi zona de pe disc, formata din 16
inregistrari (numai 11 sunt utilizate pana in prezent), fiecare avand
un nume de fisier dupa cum urmeaza:
|
Fisier
sistem
|
Nume de
fisier
|
Descriere
|
|
Master File Table
|
$Mft
|
Stocheaza continutul
volumui NTFS
|
|
Master File Table #2
|
$MftMirr
|
Duplicare a primelor 3 articole
ale Master File Table
|
|
Log File
|
$LogFile
|
Jurnal de tranzactii utilizat
pentru a recupera tranzactiile de disc in caz de eroare (ca, de exemplu,
caderi de tensiune)
|
|
Volume
|
$Volume
|
Informatii despre volum,
ca, de exemplu, numele, informatii despre versiunea de NTFS si
asa mai departe
|
|
Attribute Definition
|
$AttrDef
|
O tabela listand atributele
utilizate pe volum
|
|
Table
|
|
|
|
Root Filename Index
|
|
Continutul directorului root
|
|
Cluster Bitmap
|
$Bitmap
|
O harta de biti
aratand bitii utilizati si neutilizati de pe volum,
utilizata pentru o alocare rapida a clusterelor
|
|
Partition Boot Sector
|
$Boot
|
Programul bootstrap pentru volum
|
|
Bad Cluster File
|
$BadClus
|
Lista clusterelor stricate de pe
volum
|
|
Quota Table
|
$Quota
|
Stocheaza cota de disc
pentru utilizatorii discului
|
|
Upcase Table
|
$Upcase
|
Tabela utilizata
pentru a converti literele mici in litere mari utilizand Unicode
|
Fiecare fisier din sistemul NTFS este
prevazut cu un set de atribute (ceea ce este total diferit de atributele
din FAT). NTFS poate avea atribute pentru datele din fisier, pentru
informatii de securitate, pentru metadate sau chiar pentru numele
fisierului.
6. Sisteme
de fisiere evoluate
__________ ______ ____ __________ ______ ____ _______
Sistemele de
operare trebuie adaptate schimbarilor survenite in hardware-ul si
arhitectura calculatoarelor. Asa cum sunt proiectate masinile noi
si rapide, sistemele de operare trebuie sa se schimbe ca sa
poata profita de aparitia lor. De obicei cercetarile in domeniul
unor componente de calculator le depasesc pe acelea din alte
parti ale sistemului. Acest lucru schimba balanta
caracteristicilor utilizarii resurselor, astfel incat sistemele de operare
trebuie sa-si revizuiasca politicile in conformitate.
Chiar de la inceputul anilor 1980, industria
calculatoarelor a facut salturi rapide in domeniul vitezei procesoarelor
si a vitezei si dimensiunii memoriei. In 1982, UNIX era normal rulat
pe un VAX 11/780 care avea procesor de 1 MIPS (1 milion instructiuni pe
secunda) si 4-8 megabytes RAM. In anii 2000 masini cu procesoare
de 1000 MIPS si 256 Mb sau mai mult RAM au devenit lucruri comune pe
desktop-urile individuale. Din nefericire, tehnologia hard-discurilor nu a
tinut pasul si, desi discurile au devenit mai mari si mai
ieftine, viteza lor nu a mai crescut decat cu cel mult un ordin de marime.
Sistemele de operare UNIX care erau proiectate sa ruleze cu discuri cu
viteza moderata, dar cu memorii mici si procesoare lente, au
trebuit sa adopte aceste schimbari.
Daca
timpul pe care o aplicatie il consuma pe un sistem este de c
secunde pentru procesarea U.C.P. si i secunde pentru I/O, atunci
imbunatatirea performantei prin realizarea unui procesor
mai rapid este restransa de factorul (1+c/i). Este important de
gasit moduri pentru a reduce timpul pe care sistemul il consuma cu
operatii I/O pe disc.
Pe la mijlocul anilor 1980,
majoritatea covarsitoare a sistemelor UNIX avea sistemele de fisiere s5fs
sau FFS (Fast File System) pentru discurile locale. Amandoua
sunt adecvate pentru aplicatii generale time-sharing, dar
deficientele lor se vad atunci cand sunt folosite in medii comerciale
diverse. Interfata VNODE/VFS a facut mai usoara
adaugarea unor noi imbunatatiri a sistemului de
fisiere in UNIX. Utilizarea lui initiala era restransa la
sistemele de fisiere mici, pentru scopuri speciale, care nu cauta
sa inlocuiasca s5fs sau FFS.
Implementarea
pe disc a FFS
Spre
deosebire de s5fs, FFS
incearca sa optimizeze alocarea blocurilor pentru un fisier,
crescand viteza accesului secvential. El incearca sa aloce
blocuri continue ale fisierului pe disc oricand este posibil. Abilitatea
sa de a face acest lucru depinde de cat de plin sau cat de fragmentat este
hard-diskul. Calcule empirice arata ca el poate fi eficient pana
cand discul se apropie de 90% din capacitate.
Problema
majora este datorata intarzierii rationale pe care o introduc intre
blocuri continue. FFS este proiectat sa citeasca sau sa scrie un
singur bloc la fiecare I/O. Pentru o aplicatie care citeste un
fisier secvential, kernelul va executa o serie de citiri de blocuri
unice. Intre doua citiri consecutive, Kernelul trebuie sa verifice
daca urmatorul bloc este in cache si sa faca o cerere
I/O daca este necesar. Ca rezultat, daca doua blocuri sunt pe sectoare
consecutive pe disc, discul s-ar roti peste inceputul celui de al doilea bloc
pana cand kernelul va executa a doua citire. A doua citire va avea de
asteptat o rotatie completa de disc pana cand incepe,
cauzand o performanta foarte slaba.
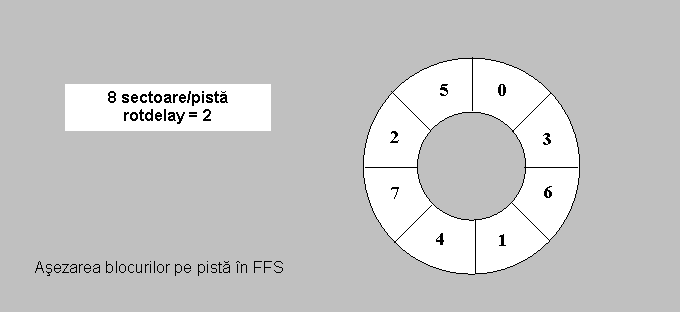
Figura Modalitatea de asezare a blocurilor la FFS
Ca sa
impiedice acest lucru, FFS calculeaza timpul care i-ar trebui kernelului
sa execute a doua citire si numarul de sectoare pe care capul
discului le-ar face in timp. Acest numar este numit intarziere de
rotatie sau rotdelay. Blocurile sunt intercalate pe disc astfel
incat blocurile logice consecutive sunt separate de blocurile rotdelay.
Pentru un disc tipic, o rotatie completa ia aproape 15 milisecunde
si kernelului ii trebuie cam 4 milisecunde intre cereri. Daca
marimea blocului este de 4Kb si fiecare pista are 8 blocuri,
rotdelay-ul ar fi 2.
Desi
acest lucru evita problema asteptarii pentru o rotatie,
inca se restrictioneaza suprapunerea (din exemplu) unei treimi
din largimea de banda a discului. Crescand marimea blocului la
8Kb se va reduce intarzierea rotdelay la 1.
Pe multe
discuri, aceasta problema dispare pentru operatiile de citire.
Aceasta din cauza ca discul are un cache de viteza mare si
orice citire incearca o pista completa in cache. Daca
urmatoarea operatie are nevoie de un bloc din pista, discul
poate satisface cererea direct din cache.
Cateva
studii despre sistemele de fisiere au aratat ca cererile de
citire pentru fisierele de date le depasesc ca numar pe
cele de scriere in raport de doi la unu. Reversul este adevarat pentru
cererile I/O pentru disc, care sunt predominant scrieri. Acest comportament neobisnuit
este cauzat de cache-ul UNIX. Deoarece aplicatiile au o puternica
localizare a referintelor in domeniul accesului la fisiere, cache-ul
are o rata de succes mare (80-90%) si satisface cele mai multe cereri
de citire fara operatiile I/O.
Operatiile
de scriere sunt terminate de obicei prin modificarea copiei cache,
fara operatii I/O cu discul. Daca totusi discul nu
este actualizat periodic, in cazul unui accident putem pierde o mare cantitate
din date. De aceea, cele mai multe implementari UNIX folosesc un proces de
actualizare, care scrie blocurile pe disc. De aici rezulta dominarea cererilor
de scriere pe disc. Prin cresterea marimii memoriei au rezultat
cache-uri mai mari si un trafic pe disc foarte redus pentru citiri.
Actualizarile
metadatelor
Anumite
cereri ale sistemului necesita cateva schimbari ale metadatelor
(metadatele sunt informatii despre fisiere - localizare, dimensiune,
nume, drepturi de acces etc.). Pentru a preveni deteriorarea sistemului de
fisiere, datorita unei caderi de sistem, aceste modificari
trebuie scrise intr-o ordine precisa. De exemplu, cand un fisier este
sters, kernelul trebuie sa stearga intrarea din director,
sa elibereze inodul si sa elibereze blocurile discului folosite
de fisier, operatii care trebuie executate in aceasta ordine
exacta, pentru a asigura consistenta in timpul unei caderi de
sistem.
Sa
presupunem ca sistemul de fisiere elibereaza inodul
inaintea stergerii intrarii din director si ca sistemul
cade intre timp. La repornire, directorul va avea o inregistrare privind un inod
nealocat, ceea ce inseamna ca nu poate fi reutilizat. Acesta este o
problema mai putin severa si ar putea fi usor reparata
cu fsck. In cazul anterior, daca inodul ar fi realocat
unui alt fisier, fsck nu s-ar sti care este inregistrarea corecta.
De
asemenea, sa presupunem ca in timp ce se trunchiaza un
fisier, sistemul de fisiere elibereaza blocurile discului
inainte de a scrie inodul modificat pe disc. Este posibil ca
aceste blocuri sa fie alocate altui fisier, al carui inod ar
putea fi scris pe disc inaintea celui al fisierului trunchiat. Daca
sistemul cade in acest moment, amandoua inodurile ar indica
aceleasi blocuri. Acest lucru nu poate fi reparat cu fsck deoarece
nu ar putea sti care inod este proprietarul de drept al
acestor blocuri.
In
sistemele de fisiere traditionale, aceasta ordine este
realizata prin scrieri sincrone. Acest lucru cauzeaza performante
scazute, mai ales cand scrierile nu sunt continue pe disc. Inca
si mai rau, operatiile NFS (Network File System) cu scrieri
sincrone pentru toate blocurile de date. In concluzie, trebuie cautat un
mod de a reduce numarul scrierilor pentru a reduce cautarile.
Recuperare
la accidente
Ordinea scrierilor metadatelor ajuta la
controlul pagubelor produse de caderile de sistem, dar nu o elimina.
In cele mai multe cazuri, efectul este de a asigura sistemul pentru
operatia de recuperare. In cazurile In care cateva sectoare de disc sunt
afectate datorita caderilor hardware, o recuperare completa nu
este posibila. Utilitarul fsck reconstruieste sistemul de
fisiere dupa o cadere. El executa urmatoarea
secventa de operatii:
1)
Citeste si verifica toate inodurile si creeaza o imagine a blocurilor
folosite.
2)
Inregistreaza numerele
inodurilor si adresele blocurilor din toate directoarele.
3)
Valideaza structura
arborelui de directoare, fiind sigur ca toate legaturile sunt
corecte.
4)
Valideaza
continutul directoarelor pentru toate fisierele.
5)
Daca un director nu poate fi atasat unui arbore in faza 2, il pune in
directorul lost-and-found.
6) Daca un director nu poate fi
atasat unui director, il pune in directorul lost-and-found.
7) Verifica imaginile pentru
fiecare grup de cilindri.
Asa
cum se vede, fsck are multe operatii de realizat, deci
masinile cu sisteme de fisiere mari pot avea intarzieri mari inainte
ca ele sa poata restarta dupa un accident. In multe medii,
astfel de intarzieri sunt inacceptabile si trebuie gasite alternative
care permit recuperari rapide la accidente.
In final, fsck are o forma limitata de
recuperare - el reduce sistemul de fisiere la un studiu consistent. Un
sistem de fisiere de incredere ar trebui sa poata mai mult.
Idealul, bineinteles, ar fi recuperarea totala, ceea ce necesita
ca fiecare operatie sa fie executata stabil inainte de a reda
controlul utilizatorului. Cum aceasta metoda este urmata de NFS
si cateva sisteme de fisiere non-UNIX, cum ar fi MS-DOS, ea
sufera de performante scazute. Un obiectiv mai rezonabil este de
a limita pagubele produse de un accident, fara a sacrifica performantele.
Gruparea
operatiilor sistemului de fisiere (Sun-FFS)
Un mod
simplu de a atinge performantele ridicate se obtine prin gruparea
(clusterizarea) operatiilor de I/O. Cele mai multe accese la
fisiere in UNIX implica citirea si scrierea unui fisier
secventional in totalitatea sa, cu toate ca acest lucru implica
cereri de sistem multiple. Pare risipitor atunci sa se restrictioneze
operatiile I/O la un singur bloc la un moment dat (de exemplu, 8
kilobytes). Multe sisteme de fisiere non-UNIX aloca fisierele in
unul sau mai multe extensii, care sunt largi, arii fizice continue pe disc. Acesta
ii da voie sistemului sa citeasca sau sa scrie
bucati mari de fisier intr-o singura operatie pe disc.
Aceste
lucruri au motivat dezvoltarea sistemului de file clustering in FFS
la SunOS, care a fost mai tarziu incorporata in SVR4 si 4.4BSD.
Scopul lui Sun-FFS este de a atinge performante ridicate prin
operatii I/O de o mare granularitate, fara a schimba structura
de pe disc a sistemului de fisiere. Implementarea sa necesita
doar un numar mic de schimbari in rutinele interne ale kernelului.
Alocatorul
de blocuri pe disc FFS se descurca de minune alocand blocuri continue unui
fisier, folosind un algoritm inteligent care anticipa urmatoarele
cereri de alocare.
Sun-FFS
seteaza factorul rotdelay la zero, deoarece scopul este de a evita
plata penalizarii intercalarilor rationale. Un camp denumit maxconting
prezent in superbloc contine numarul de blocuri continue de stocare
inaintea aplicarii spatiului rotdelay. Acest camp este de
obicei setat la unu, dar nu are nici un sens atata timp cat rotdelay
este zero. De aceea, Sun-FFS foloseste acest camp pentru a stoca
marimea clusterului dorit. Acest lucru ii permit superblocului sa
stocheze un parametru in plus fara sa-si schimbe structura.
De cate ori
se face o cerere de acces pe disc, este de dorit a se citi intreg. Aceasta s-a
realizat prin modificarea interfetei rutinei bmap (implementarea
traditionala FFS, bamp() ia un numar de bloc logic
si returneaza numarul pentru blocul fizic. Sun-FFS schimba
aceasta interfata pentru ca bamp sa returneze o
valoare contigsize aditionala, ceea ce specifica
continutul fizic al fisierului pornind de la un bloc anume.
Sun-FFS
foloseste contigsize pentru a citi un cluster intreg la un moment
dat. In unele cazuri, alocatorul nu poate gasi un cluster complet si
valoarea contigsize returnata de bamp() este mai mica
decat maxconfig. Logica ahead este bazata pe contigsize-ul
returnat de bmap() si nu de marimea clusterului ideal.
Utilizarea
jurnalului
Multe sisteme de fisiere moderne folosesc o
tehnica numita logging journalling pentru a adresa multe din
functiile unui sistem de fisiere traditionale. Conceptul de
baza este de a inregistra toate schimbarile de sistem intr-un log.
Log-ul este scris secventional, pe bucati mari, ceea ce
creeaza o utilizare a discului mai eficienta si performante
ridicate. Dupa un accident, numai coada log-ului trebuie
examinata, ceea ce inseamna recuperare rapida si incredere
ridicata.
Desi avantajele par
atractive, sunt cateva probleme complexe. Au fost numeroase inplementari
de fisiere de tip log, in cercetare de industrie si fiecare
avea arhitecturi diferite. Sa identificam principalele caracteristici
care diferentiaza aceste sisteme pentru fiecare dintre ele si
examinam cateva dintre cele mai importante proiecte in detaliu.
Caracteristici
de baza
Pentru a proiecta un sistem de fisiere de tip log
trebuie luate cateva decizii:
Ce
sa 'logheze'-
Aceste sisteme de fisiere se impart in doua tabere: acelea care inregistreaza
toate modificarile si acelea care inregistreaza doar
schimbarile metadatelor. Log-urile metadatelor pot restrictiona
mai mult numai la anumite operatii selectate de exemplu, ele ar putea
sa inregistreze schimbarile din data fisier a proprietarului, permisiunile
si sa inregistreze doar acele schimbari care ar afecta sistemul
grav.
Operatii
sau valori - Un log poate inregistra operatii individuale,
rezultatul acestor operatii. Primul este folositor, de exemplu,
inregistram schimbarile imaginii alocarii blocurilor pe disc.
Deoarece fiecare schimbare consuma doar cativa biti, log-ul
operatiilor ar putea sa incapa intr-o inregistrare
compacta. Cu toate acestea, cand inregistram scrieri de date, este de
preferat sa scriem intregul continut al blocului modificat in log.
Supliment sau substitut
- sistemele de fisiere cu log-uri
atasate pastreaza structura traditionala pe disc, cum
ar fi inoduri si superblocuri,
folosesc log-ul ca o inregistrare
suplimentara.
Log-uri redo
si undo - Exista doua
tipuri de log-uri: redo-only si undo-redo. Un log redo-only inregistreaza doar datele
modificate. Un log undo-red inregistreaza vechea si noua valoare a
datelor. Log-ul redo-only simplifica
recuperarea la accident, dar constrange ordonarea scrierilor in log. Log-ul undo-red este mai mare si
are mecanisme de recuperare mai complexe, dar asigura o concurenta
mai mare in timpul folosirii normale.
Recuperare - intr-un sistem de fisiere structurat pe log
este nevoie de un mod eficient de recuperare a datelor din log. Desi asteptarile
normale sunt ca un cache mai mare ar satisface cele mai multe citiri, trebuie
asigurat ca acel cache poate fi accesat intr-un timp rezonabil.
Sisteme de fisiere structurate pe log
Sistemele de fisiere
structurate pe log folosesc o singura structura log secvential. Ideea
este de a strange un numar mare de schimbari ale sistemului intr-un log
larg si de a-l scrie pe disc intr-o singura operatie.
Avantajele par impresionante. Deoarece
scrierile sunt mereu la coada log-ului, ele sunt toate secventiale
si cautarile pe disc sunt eliminate. Fiecare scriere in log
transfera un volum mare de date, de obicei o pista intreaga de
pe disc. Aceasta elimina nevoia de intercalari rotationale
si ii permite sistemului de fisiere sa foloseasca
toata largimea de banda a discului. Recuperarea la accident este
foarte rapida - sistemul de fisiere localizeaza ultima intrare in
log
si o foloseste pentru a reconstrui sistemul.
Toate acestea sunt bune atata timp
cat doar scriem in log, dar ce se intampla cand dorim sa recuperam
date din el? Mecanismele traditionale de localizare a datelor pe disc nu
mai sunt la indemana si trebuie cautat prin log pentru datele care
ne trebuie. Pe un sistem intr-o stare stabila (unul care a mers corect o
vreme), un cache mare ar atinge usor o rata de acuratete mai
mare de 90%. Pentru acele blocuri care trebuie accesate de pe disc, trebuie un
mod de a localiza date in log in timp rezonabil.
4.4BSD foloseste un sistem de
fisiere structurat pe log, care poarta numele
BSD-LFS.
Sistemul de fisiere structurat pe log 4.4BSD
BSD-LFS
dedica intregul disc log-ului,
care este singura reprezentare persistenta a sistemului de fisiere.
Toate scrierile se realizeaza la coada log-ului si colectarea
informatiilor inutile se face prin procesul de "curatare". Log-ul
este impartit in segmente de marime fixa. Fiecare segment
are un pointer catre urmatorul.
BSD-LFS pastreaza structurile de directoare si inoduri,
ca si schema de blocuri de indirectare pentru adresarea blocurilor logice
a fisierelor largi. Cea mai importanta problema este cum sa
se gaseasca un inod. FFS-ul original configura inodorile
static pe disc, in locatii fixe, in grupuri de cilindre diferite.
In BSD-LFS, inodurile sunt scrise pe disc ca
parte a log-ului si aici nu au adrese fixe. De fiecare data cand
un inod
este modificat, este scris intr-o locatie noua in log Aceasta necesita o structura de date aditionala
numita inode map, care memoreaza
adresa curenta pe disc a inodului.
Desi BSD-LFS incearca sa scrie un segment complet la un moment
dat acest lucru nu este posibil mereu. Un segment partial ar trebui scris
datorita dimensiunii memoriei (cache-ul fiind plin) sau cererilor fsync.
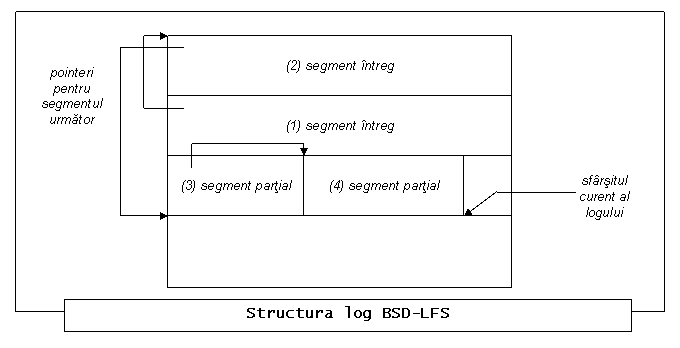
Figura 6. Fisier
Log la BSD-LFS
De aceea, un segment ce descrie o partitionare
fizica a discului, este facut din unul sau mai multe segmente partiale.
Fiecare
segment partial are un antet de segment, care contine urmatoarele
informatii folosite in timpul unei recuperari de accident:
Sume de verificare, care sunt folosite la
detectarea erorilor de mediu si scrierilor incomplete.
Adresa discului a fiecarui inode
din segmentul partial.
Pentru fiecare fisier care are blocuri
de date localizate in segment, numarul inodului si numarul
versiunii inodului, ca si numerele blocurilor logice.
Timpul crearii, flaguri etc.
Aceste sisteme mai retin si un tabel de
utilizare a segmentelor, care memoreaza numarul octetilor din
fiecare segment si timpul cand segmentul a fost ultima data
modificat. Procesul cleaner foloseste
aceste informatii ca sa aleaga segmentele ce trebuie sterse.
Scrierea fisierului log
BSD-LFS aduna blocuri
modificate pana cand are destul pentru a umple un segment complet. Un
segment partial trebuie scris datorita unei cereri NFS (Network File
Sistem) sau datorit; umplerii memoriei. Daca controlerul discului
suporta operatii I/O, blocurile sunt scrise direct din cache. Daca
nu, kernelul poate aloca temporar, 64 KB de buffere pentru transfer.
Pregatind transferul,
blocurile de pe disc sunt sortate dupa numerele de bloc logic din fisiere.
Adresele discului sunt atasate fiecarui bloc in acest moment si inodurile
trebuie sa fie modificate ca sa indice aceste adrese.
De fiecare data cand un boc
este modificat, este scris intr-o noua locatie in log.
Aceasta inseamna ca toate copiile vechi ale blocului din log
au devenit inutile si pot fi sterse de procesul cleaner.
Fiecare operatie de scriere
sterge toate datele modificate din cache, ceea ce inseamna ca log-ul
contine toate informatiile necesare pentru o recuperare totala.
Harta inodurilor si tabelul utilizarii segmentelor
reprezinta informatie redundanta, ceea ce poate deriva din log.
Aceste doua structuri sunt stocate intr-un fisier normal, read-only
numit ifile. Ifile poate fi accesat de
utilizatori ca si orice alt fisier, dar este special in sensul
ca modificarile ifile nu sunt scrise in fiecare
segment. In schimb, sistemul defineste puncte de verificare periodice, in
timpul carora el scrie ifile-ul pe disc.
III.2 Apeluri sistem UNIX
Intern,
gestionarea fisierelor se face prin intermediul a trei tabele, si
anume:
a. Tabela de descriptori. Aceasta este proprie
fiecarui proces. Fiecarui
fisier deschis ii corespunde o
intrare in aceasta tabela, indicele acesteia fiind considerat descriptorul fisierului.
Caracteristicile memorate de intrarile din aceasta tabela pot fi
citite prin intermediul structurii ofile_t
descrisa in "sys/user.h".
La lansare, orice proces are, din start, deschise trei fisiere,
corespunzatoare descriptorilor 0, 1 si 2 care sunt : intrarea standard
(standard input-stdin), iesirea
standard (standard output-stdout)
si iesirea pentru erori (standard error-stderr). Implicit, aceste fisiere corespund terminalului de
lansare. Acesti descriptori pot fi referiti prin constantele
simbolice STDIN_FILENO, STDOUT_FILENO si STDERR_FILENO.
b.
Tabela de fisiere
deschise. Aceasta tabela este partajata de catre toate
procesele. Orice intrare din tabela de descriptori a oricarui proces
memoreaza adresa unei intrari din aceasta tabela. La
deschiderea unui fisier de catre un proces, se creaza o
noua intrare in tabela de descriptori a procesului si o noua
intrare in tabela de fisiere deschise. Intrarile in aceasta tabela
memoreaza:
numarul total de descriptori ce pointeaza catre
aceasta.
modul
de deschidere al fisierului
pozitia
curenta (offset)
un
pointer catre o intrare in a treia tabela si anume:
c.
Tabela de i-noduri
din memorie. La deschiderea unui fisier, in caz
ca datele despre i-nodul corespunzator nu se gasesc deja in
aceasta tabela, se creeaza o noua intrare. Intrarile din aceasta tabela
memoreaza:
numarul total al intrarilor din tabela de
fisiere deschise ce pointeaza
catre
aceasta.
identificatorul
discului de origine
numarul
de i-nod
starea
acestuia : daca informatiile din i-nod au fost modificate ulterior
incarcarii
acestuia in memorie sau daca un proces a impus un blocaj.
Din SHELL atributele i-nodurilor se pot vizualiza cu ajutorul comenzii
ls -l
Programatorii au la
dispozitie structura urmatoare:
#include <sys/types.h>
#include <sys/stat.h>
struct
stat ;
Toate tipurile de date corespunzatoare campurilor sunt de tip
intreg si definite in headere. Cu aceasta ocazie, mentionam
ca tipul de date time_t
exprima numarul de secunde scurse de la 1 Ianuarie 1970, data de
referinta penru sistemele de tip UNIX. Cu aceasta
explicatie consideram ca este suficient de clar modul de
interpretare a valorii campurilor, cu exceptia lui st_mode care memoreaza pe biti, atat tipul
fisierului, cat si cele trei tipuri de drepturi (citire, scriere, executie)
corespunzator celor trei categorii de utilizatori: proprietar (user), grup
proprietar (group) si ceilalti (other).
Exploatarea acestui camp se face
cu ajutorul unor masti definite prin constante simbolice si
anume:
S_IRUSR drept de
citire pentru proprietar
S_IWUSR drept de
scriere pentru proprietar
S_IXUSR drept de
lansare in executie pentru proprietar.
Valorile tuturor
celor trei biti corespunzatori drepturilor proprietarului pot fi
recuperate cu ajutorul mastii S_IRWXU.
S_IRGRP drept de citire pentru grupul
proprietar
S_IWGRP drept de
scriere pentru grupul proprietar
S_IXGRP drept de
lansare in executie pentru grupul proprietar. Valorile tuturor celor trei biti
corespunzatori drepturilor grupului proprietar pot fi recuperate cu
ajutorul mastii S_IRWXG.
S_IROTH drept de
citire pentru ceilalti utilizatori
S_IWOTH drept de
scriere pentru ceilalti utilizatori
S_IXOTH drept de
lansare in executie pentru ceilalti utilizatori Valorile tuturor celor trei biti
corespunzatori drepturilor pentru ceilalti utilizatori pot fi
recuperate cu ajutorul mastii S_IRWXO.
Mai avem la dispozitie doua masti
pentru recuperarea din acelasi camp a altor doua caracterisitici pe
bit : set-uid (masca S_ISUID)
si set-gid (masca S_ISGID). Semnificatiile
acestor doua informatii le vom explica ulterior.
De exemplu, masca pentru
drepturile rwxr-x-x va fi
alcatuita cu una din urmatoarele doua disjunctii:
S_IRWXU
| S_IRGRP | S_IXGRP | S_IXOTH
sau
S_IRUSR | S_IWUSR | S_IXUSR | S_IRGRP | S_IXGRP | S_IXOTH.
Testul pentru tipul de fisier se poate face atat
cu ajutorul unor masti, dar si
cu ajutorul unor expresii
macro-definite (macro-uri), care reprezinta expresii ce dau ca rezultat 1
sau 0, in functie de faptul daca fisierul este de tipul respectiv
sau nu.
Tip de fisier Masca Macro__
Obisnuit _S_IFREG S_ISREG
Special bloc _S_IFBLK S_ISBLK
Special caracter _S_IFCHR S_ISCHR
Director _S_IFDIR S_ISDIR
Tub _S_IFIFO S_ISFIFO
Legatura simbolica S_IFLNK S_ISLNK
Socket S_IFSOCK S_ISSOCK
Mentionam
ca nu este o eroare faptul ca numele simbolic al ultimelor doua
masti nu incepe cu caracterul '_'. Acestea provin din versiuni anterioare normei POSIX.
Exemplu
struct stat st;
....
if (st.st_mode & _S_IFDIR)
if (S_ISDIR(st.st_mode)
if (st.st_mode & (S_IRGRP | S_IXGRP) ==
S_IRGRP
| S_IXGRP
Atentie.
Macro-definitiile
prezentate mai sus sunt valabile pe HP-UX. Pe alte versiuni avem la
dispozitie maco-definitii similare, dar este posibil ca numele
acestora sa difere, in mica masura, ce-i drept.
Sfatuim programatorul sa consulte de fiecare data manualele de
utilizare ale versiuni de sistem de operare cu care lucreaza.
Apelul cu care se pot
incarca datele referitoare la un i-nod intr-o structura de tipul stat sunt
#include <sys/types.h>
#include <sys/stat.h>
int stat
(char *nume-fisier, struct stat *ptr_stat);
Apelul incarca in structura a carei
adresa este data in al doilea parametru, caracteristicile i-nodului
fisierului desemnat de primul parametru. Pentru succesul acestui apel, nu
sunt necesare drepturi asupra fisierului, ci numai drepturile de rigoare
asupra directoarelor ce intervin in localizarea fisierului invocat prin
nume. In caz ca aceste drepturi nu exista, variabila errno va lua valoarea EACCESS. O alta cauza
posibila a insuccesului acestui apel este inexistenta fisierului
referit. In acest caz, errno va lua
valoarea ENOENT.
Consultarea unui fisier de
tip legatura simbolica cu ajutorul apelului stat va conduce la furnizarea caracteristicilor i-nodului
catre care pointeaza legatura, si, in consecinta,
tipul de fisier obtinut nu va fi niciodata legatura
simbolica. Pentru a obtine caracteristicile i-nodului de tip legatura
simbolica se poate folosi apelul :
#include <sys/stat.h>
int lstat (char *nume_fisier,
struct stat *ptr);
Primitiva cu ajutorul careia se deschid
fisiere este:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open (char *nume_fisier,
int mod_deschidere, mode_t drepturi)
Mentionam faptul ca al treilea parametru nu este
obligatoriu de furnizat decat atunci cand este posibila crearea unui nou
fisier (i-nod) si, in acest caz, acest argument reprezinta
drepturile de acces si este construit prin disjunctie dintre
constantele prezentate la descrierea campului st_mode al structurii stat.
Acest apel este recomandabil,
in special, pentru fisierele de tip obisnuit. Pentru alte tipuri de
fisiere exista apeluri specifice pentru deschidere.
Acest apel poate deveni,
in anumite conditii, blocant. De exemplu, deschiderea pentru scriere a
unui tub fara sa existe un descriptor deschis pentru citire. In
acest caz apelul asteapta pana cand un alt proces face o
deschidere pentru citire. Parametrul al doilea se furnizeaza ca o
disjunctie intre constante simbolice din lista de mai jos:
Obligatoriu
una si numai una dintre O_RDONLY (deschidere
exclusiv pentru
citire), O_WRONLY (deschidere
exclusiv pentru scriere) si O_RDWR
(deschidere pentru citire si scriere simultan).
O_TRUNC - Daca
fisierul exista si este de tip obisnuit, informatia
continuta in acesta se trunchiaza, adica i se reduce
dimensiunea la zero octeti.
O_CREAT - Daca fisierul
nu exista, se creaza un nou i-nod de tip
obisnuit, ce are drept proprietar si grup proprietar,
proprietarul si, respectiv grupul proprietar al procesului, si, ca
drepturi de acces cele mentionate in al treilea parametru filtrate prin
masca de drepturi implicite pentru crearea fisierelor. Aceasta
masca se poate vizualiza sau modifica cu ajutorul comenzii SHELL umask .
O_EXCL - Nu are efect decat in prezenta optiunii O_CREAT. In
acest caz, existenta prealabila a fisierului conduce la
esecul apelului (se doreste exclusiv creare de fisier nou
si nicidecum deschiderea unui fisier existent). Ca apelul sa fie
incununat de succes trebuie sa existe drepturi de scriere in director.
O_NOCTTY - Daca fisierul deschis corespunde unui
terminal,
acesta nu devine terminal de control al procesului.
O_APPEND - Toate scrierile se fac
la sfarsitul fisierului. In cazul
unei operatiuni de scriere, pozitia curenta se muta la
sfarsitul fisierului.
O_NONBLOCK - Deschiderile blocante esueaza, adica
se iese din
apel
fara a se mai astepta inlaturarea cauzei blocajului si
se furnizeaza cod de retur -1
catre apelant, iar errno ia
valoarea EAGAIN. Citirile si
scriereile ulterioare se trateaza, de asemenea, in mod neblocant.
O_SYNC - Scrierile
blocheaza procesul pana la copierea datelor pe
disc.
O_NDELAY - Citirile si scrierile blocante
esueaza, adica se iese din
apel
fara a se mai astepta inlaturarea cauzei blocajului, se
furnizeaza cod de retur -1
catre apelant, iar errno ia
valoarea EAGAIN.
In caz de eroare se returneaza
-1, iar in caz de succes se creaza o noua intrare in tabela de
descriptori si se returneaza indexul acesteia. Un cod de retur
ne-negativ inseamna succes si reprezinta descriptorul ce va fi
folosit la operatiile urmatoare. In plus:
pozitia curenta in fisier este 0.
se creaza o noua intrare in tabela de
fisiere deschise ce are un
descriptor ce
pointeaza spre aceasta.
in
intrarea din tabela de i-noduri din memorie corespunzatoare
fisierului deschis, numarul de intrari din tabela de
fisiere deschise ce pointeaza catre aceasta este incrementat.
descriptorul ramane deschis pana la terminarea
procesului, mai putin
situatia in
care s-a cerut in mod expres inchiderea sa prin apel la primitiva close.
Observatii
a.
Testul asupra drepturilor de acces se face numai la
deschidere. Odata
descriptorul
deschis, acesta ramane valid in ciuda unor modificari ulterioare ale
drepturilor de acces efectuate de alt proces.
b.
Nu este garantat faptul ca valoarea de retur
reprezinta indexul celui
mai mic
descriptor nefolosit, chiar daca experimental se poate constata acest
fapt.
c.
O
deschidere in modul O_RDWR nu este
acelasi lucru cu doua
deschideri, una
in mod O_RDONLY si alta in mod O_WRONLY, deoarece in acest din
urma caz cei doi descriptori gestioneaza fiecare propria sa
pozitie curenta.
Primitiva folosita pentru inchiderea fisierelor este
#include
<unistd.h>
int close (int desc);
unde argumentul
reprezinta descriptorul recuperat cu open.
Efectele acestui apel sunt urmatoarele:
se ridica toate blocajele puse de proces asupra fisierului,
chiar daca
acestea au fost puse prin intermediul altui descriptor.
se va decrementa numarul de descriptori din intrarea
corespunzatoare
din tabela de fisiere deschise.
daca acest numar devine nul, se elibereaza
intrarea din tabela de
fisiere deschise si in intrarea din tabela de i-noduri din
memorie se decrementeaza numarul de intrari din tabela de
fisiere deschise ce pointeaza spre aceasta.
daca numarul de mai sus devine nul, se elibereaza intrarea din
tabela
de i-noduri din memorie si in caz ca numarul de
legaturi fizice ale fisierului este, de asemenea, nul, fisierul
este sters.
Citirea
fisierelor se face cu ajutorul apelului:
#include
<unistd.h>
ssize_t read
(int desc, void *ptr, size_t nr_oct);
Acest apel citeste din fisierul
desemnat de descriptorul desc, nr_oct
octeti, pe care ii va depune in memorie la adresa desemnata de ptr.
Pentru fisiere de tip obisnuit, procedura de citire se
desfasoara astfel:
1.
Se returneaza -1 in caz de esec (descriptor
invalid sau care nu este
deschis in citire, de exemplu)
2. Daca nu exista un blocaj care
sa impiedice citirea atunci: Fie rest_oct
numarul de octeti de la pozitia curenta pana la
sfarsitul fisierului. Se vor citi k = min(nr_oct, rest_oct). Codul de retur va fi k, adica numarul de
octeti efectiv cititi. Pozitia curenta se va incrementa cu k. Remarcam ca daca
pozitia curenta era de la inceput la sfarsitul fisierului,
valoarea returnata va fi 0.
3. Daca exista un blocaj care sa
impiedice citirea datelor, apelul ramane
blocat in
asteptarea ridicarii blocajului, in situatia in care indicatorii
O_NONBLOCK sau O_NDELAY nu au fost pozitionati la deschidere. In caz contrar, codul
de retur este -1, iar errno ia
valoarea EAGAIN.
Exemplu
Presupunem ca avem
un fisier care are drept inregistrari date de tipul
typedef struct MY_STR;
Pentru a citi 40 de asemenea structuri putem folosi secventa:
int nr;
MY_STR *ptr;
ptr = (MY_STR *)malloc (40 * sizeof (MY_STR));
while ((nr=read(desc, ptr, 40 * sizeof (MY_STR))>0)
unde nr impartit la sizeof (MY_STR) reprezinta numarul de structuri efectiv citite.
In caz ca acesta este mai mic decat 40, in mod sigur, la urmatorul
apel codul de retur va fi 0, deoarece s-a ajuns la sfarsitul
fisierului.
Scrierea in fisiere se face
cu ajutorul apelului:
#include <unistd.h>
ssize_t write (int desc,
void *ptr, size_t nr_oct);
Acest apel scrie in fisierul desemnat de descriptorul desc, nr_oct octeti,
cititi din memorie de la adresa desemnata de ptr. Pentru fisiere
de tip obisnuit, procedura de scriere se desfasoara astfel:
1.
Se returneaza -1 in caz de esec (descriptor
invalid sau care nu este
deschis in scriere, de exemplu)
2.
Daca nu exista un blocaj care sa impiedice
scrierea, atunci octetii se
vor scrie in fisier, la sfarsitul acestuia sau la pozitia
curenta, in functie de faptul daca indicatorul O_APPEND a fost pozitionat sau nu.
Functia returneaza numarul de octeti scrisi. In caz
ca se returneaza mai putin de nr_oct, aceasta semnifica eroare (disc plin, de exemplu).
Scrierea octetilor nu se face direct pe disc, ci prin intermediul memoriei
cache, mai putin situatia in care s-a folosit la deschidere
optiunea O_SYNC.
3. Daca exista un blocaj care
sa impiedice scrierea datelor, apelul
ramane
blocat in asteptarea ridicarii blocajului, in situatia in care
indicatorii O_NONBLOCK sau O_NDELAY nu au fost
pozitionati la deschidere. In caz contrar, codul
de retur este -1, iar errno ia
valoarea EAGAIN.
Exemplu
Reluam exemplul
precedent. Scrierea a 40 de structuri de tipul MY_STRUCT se poate realiza astfel:
MY_STRUCT vec[40];
..
/* secventa de initializare a datelor */
if (write(desc, vec,
40*sizeof(MY_STRUCT)) !=
40*sizeof(MY_STRUCT))
Prin duplicare, un proces poate obtine mai
multi descriptori care pointeaza spre aceeasi intrare din tabela
de fisiere deschise. Un prim apel este:
#include
<unistd.h>
int
dup(int desc);
Parametrul reprezinta valoarea unui
descriptor valid, iar apelul returneaza, in caz de succes, valoarea noului
descriptor ce duplica pe primul. Acest apel garanteaza duplicarea in indexul cel mai mic
corespunzator unei intrari libere in tabela de descriptori ai
procesului.
Apelul care este prezentat in continuare are
prototipul urmator:
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
int fcntl (int desc,
int comanda,.)
Primul parametru reprezinta o intrare valida din tabela de
descriptori, iar al doilea desemneaza comanda ce urmeaza a fi
executata, valoarea acestuia fiind furnizata prin intermediul unor
constante simbolice. Natura acestei comenzi poate impune prezenta celui
de al treilea parametru, tipul de date al acestuia precum si modul de
interpretare al codului de retur (-1 inseamna, ca de obicei, esec).
O prima categorie de comenzi este aceea care
se refera la citirea sau modificarea atributelor descriptorului. Comanda F_GETFD, determina returnarea
atributelor descriptorului sub forma unui intreg, a carui valoare este
interpretata pe biti. Comanda F_SETFD,
determina instalarea de noi atribute, caz in care este necesara
pasarea celui de al treilea parametru, de tip int, care contine valoarea noilor atribute. Exemplificam,
in continuare, modul de instalare al atributului FD_CLOEXEC, ce are ca efect inchiderea descriptorului imediat
dupa un apel din familia exec. De
altfel, acest atribut este singurul prevazut expres de norma POSIX ca
fiind modificabil.
int desc, atribut;
atribut = fcntl(desc, F_GETFD); /* citire valoare */
atribut |= FD_CLOEXEC; /* noua
valoare */
fcntl(desc, F_SETFD, atribut); /* instalare */
Alta categorie de comenzi este aceea pentru
citirea sau modificarea modului de deschidere. Se pot seta sau reseta numai
indicatorii O_APPEND, O_NONBLOCK,
O_NDELAY si O_SYNC. Atragem
atentia asupra faptului ca aceste caracteristici sunt ale tabelei de
fisiere deschise si, in consecinta, orice modificare a
acestora afecteaza toti descriptorii ce pointeaza spre intrarea
respectiva din tabela de fisiere deschise. Comanda F_GETFL, determina returnarea
modului de deschidere sub forma unui intreg, a carui valoare este
interpretata pe biti. Comanda F_SETFL,
determina instalarea noului mod de deschidere, caz in care este
necesara pasarea celui de al treilea parametru, de tip int, care contine valoarea de
instalat. Exemplificam, in continuare, modul de setare si resetare al
atributului O_APPEND.
int desc,
atribut;
atribut = fcntl(desc, F_GETFL); /* citire valoare */
atribut |= O_APPEND; /* setare */
fcntl(desc,
F_SETFL, atribut); /* instalare */
atribut = fcntl(desc, F_GETFL); /* citire valoare */
atribut &= ~O_APPEND; /* resetare */
fcntl(desc,
F_SETFL, atribut); /* instalare */
Comanda F_DUPFD,
duplica descriptorul in intrarea libera cu cel mai mic indice din tabela de descriptori, care este
mai mare sau egal cu valoarea celui de al treilea parametru, care este de tip int. Codul de retur este valoarea
noului descriptor.
Una din functionalitatile
principale ale apelului fcntl este
aceea de a gestiona blocajele asupra fisierelor. Un blocaj se
inregistreaza la nivelul tabelei de i-noduri din memorie, si este
proprietatea exclusiva a procesului care l-a pus. In consecinta,
numai acesta poate ridica blocajul. Daca nu o face, blocajul va persista
pana la terminarea procesului respectiv.
Caracteristicile unui blocaj sunt:
zona blocata, ce poate fi intre doua
pozitii din fisier sau de la
o pozitie din fisier pana la sfarsitul fisierului.
tipul blocajului: partajat
sau exclusiv. Un blocaj partajat poate
coexista cu alte
blocaje partajate, pe cand existenta unui blocaj exclusiv, impiedica
instalarea altor blocaje pana la deblocare.
modul
de operare : consultativ,
fara sa conduca efectiv la blocarea
operatiilor
de citire/scriere, dar impiedica
punerea de alte blocaje incompatibile, si imperativ ce duce la blocarea operatiilor de citire/scriere in
zona blocata astfel: un blocaj imperativ partajat blocheaza
operatiile de scriere, iar un blocaj imperativ exclusiv blocheaza
atat operatiile de scriere cat si cele de citire din zona
blocata.
Pentru reprezentarea caracteristicilor unui blocaj, programatorul are
la dispozitie urmatoarea structura definita in
fisierele header:
struct flock ;
unde valorile campurilor au urmatoarea semnificatie:
l_type determina tipul
blocajului si poate avea urmatoarele valori:
F_RDLCK, corespunzatoare
tipului partajat, F_WRLCK,
corespunzatoare tipului exclusiv si F_UNLCK ce corespunde unei cereri de deblocare. Punerea unui blocaj
partajat se poate face numai pentru descriptorii deschisi pentru citire,
iar pentru punerea unui blocaj exclusiv este necesar ca descriptorul respectiv
sa fie deschis pentru scriere.
l_whence poate avea urmatoarele valori: SEEK_SET, ce semnifica
inceputul
fisierului, SEEK_CUR, ce
semnifica pozitia curenta si SEEK_END care semnifica sfarsitul fisierului.
Pozitia de start a zonei blocate va fi
calculata cu formula
l_whence +l_start
l_len indica lungimea zonei blocate in octeti.
Valoarea 0 a acestui
camp
semnifica faptul ca zona blocata se intinde pana la
sfarsitul fisierului, lungimea acesteia modificandu-se odata cu
dimensiunea fisierului.
pid_t indica procesul proprietar al blocajului.
Gestiunea blocajelor se face cu ajutorul apelului fcntl, pasand drept al
treilea parametru un pointer catre o structura de tip flock, iar drept comanda una din urmatoarele valori:
F_SETLCK, ce semnifica o
tentativa de punere a unui blocaj cu
caracter consultativ. Parametrul al treilea este de intrare, in acest caz,
si campurile structurii de tip flock,
trebuie umplute cu caracteristicile blocajului. Codul de retur este 0 in caz de
succes si -1 altfel. Cauzele esecului ar putes fi: descriptor
incorect (errno va avea valoarea EACCESS), existenta
prealabila a unui blocaj incompatibil (errno va avea valoarea EAGAIN) si interblocaj (deadlock),
caz in care errno va avea valoarea EDEADLK. Notiunea de interblocaj va fi explicata
ulterior.
F_SETLKW, ce are acelasi efect cu F_SETLCK cu deosebirea ca
se doreste punerea unui blocaj cu caracter imperativ si ca
acest apel este blocant in sensul ca se va astepta, daca este
cazul, disparitia tuturor blocajelor incompatibile existente. Acest apel
este intreruptibil. In caz de intrerupere codul de retur va fi -1 iar errno va avea valoarea EINTR.
F_GETLCK, test de existenta a unui blocaj
incompatibil cu cel
descris de al treilea parametru. Codul de retur este totdeauna 0. Daca
nu exista blocaj incompatibil se va pune valoarea F_UNLCK in campul l_type
al structurii de tip flock. In caz
contrar campurile structurii de tip flock
vor contine caracteristicile
blocajului incompatibil. Este evident ca, daca in urma acestui apel
se constata inexistenta unui blocaj incompatibil cu cel desemnat, o
tentativa ulterioara de punere efectiva a acestui blocaj poate
esua, deoarece, intre timp, alt proces poate pune un alt blocaj.
Un proces poate debloca o zona din cea blocata anterior,
spargand astfel
blocajul in doua blocaje pe doua zone de dimensiuni mai reduse
si sa schimbe tipul blocajului, daca este posibil. Schimbarea
tipului blocajului din partajat in exclusiv necesita, pentru
reusita, absenta oricarui alt blocaj pe zona blocata.
Situatia de interblocaj, cunoscuta si sub
numele de deadlock se produce cand
doua procese ajung in situatia de a se astepta unul pe altul
pentru ridicarea unui blocaj. De exemplu. procesul P1 pune blocajul imperativ B1,
iar procesul P2 pune blocajul
imperativ B2. Ulterior P1 va incerca sa puna un
blocaj imperativ incompatibil cu B2,
iar P2 va incerca sa puna
un blocaj imperativ incompatibil cu B1. In
acest caz cele doua procese se vor astepta unul pe altul. Sistemul de
operare sesizeaza acest interblocaj si va alege unul dintre procese
drept "victima", punand capat asteptarii procesului in
apelul sistem. Codul de retur pentru apelul efectuat de "victima" este in
acest caz -1, iar errno va lua
valoarea EDEADLK.
Pe multe versiuni de
sistem, blocajele imperative nu actioneaza efectiv, impiedicand
scrierile sau, eventual, citirile asupra unui fisier decat daca
acesta are indicatorul set-gid setat
si fara drept de executie pentru grupul proprietar.
Prototipul apelului
mentionat in titlul paragrafului este:
# include <unistd.h>
off_t lseek (int desc, off_t pozitie, int orig);
si are
drept efect schimbarea pozitiei curente in fisier fara a
efectua, in prealabil, o operatie de citire sau scriere. desc reprezinta, ca de obicei,
descriptorul, iar pozitie poate lua
una din valorile SEEK_SET (inceput
de fisier), SEEK_CUR
(pozitie curenta) sau SEEK_END
(sfarsit de fisier). Noua pozitie curenta se calculeaza
dupa formula pozitie + orig,
si reprezinta codul de retur al apelului, in caz de succes. In caz de
insucces se returneaza -1. Putem sa ne pozitionam dincolo
de sfarsitul fisierului si sa obtinem, prin scrieri
ulterioare, fisiere ce nu sunt contigue, dar nu ne vom putea
pozitiona niciodata inaintea inceputului fisierului.
Fisierele speciale de tip
director pot fi deschise cu open si
citite cu read. Acest mod de
abordare a problemei citirii unui director este, insa, complet
contraindicata deoarece structura acestor fisiere se poate modifica
de la o versiune la alta a sistemului de operare. Singurul lucru pe care il
stim cu certitudine este acela ca directorul realizeaza
corespondenta intre i-nod si numele unei legaturi fizice.
Fisierul header dirent.h, contine, printre altele,
definitia tipului de date DIR,
ce descrie caracteristicile directorului, precum si a structurii dirent, ce contine
caracteristicile unei intrari in director, printre care numele in campul char d_name[NAME_MAX];
Atentie! Este usor de ghicit faptul ca tipul de date
DIR este o structura. Cu toate
acestea, programatorului trebuie sa-i fie transparent acest lucru. Dimpotriva, acesta poate folosi, de
exemplu, campurile structurilor stat,
flock, dirent,. descrise ca atare in documentatie.
Deschiderea unui
fisier de tip director se poate face prin intermediul apelului:
#include <dirent.h>
DIR
*opendir (char *nume_dir);
ce deschide directorul avand numele dat in argument. In caz de eroare se
returneaza NULL. Codul de retur
va fi folosit, in continuare, pentru exploatarea directorului.
Citirea intrarii
urmatoare din director se poate face cu apelul:
#include <dirent.h>
struct dirent *readdir(DIR *p);
Acest apel va furniza, dupa deschidere, rand pe rand, intrarile din
director, inclusiv cele numite "." si "..". Codul de retur NULL, semnifica sfarsitul
parcurgerii directorului sau o eroare.
Apelul:
#include <dirent.h>
void rewidndir (DIR *p);
repozitioneaza intrarea intr-un director deschis, la inceputul
acestuia.
Inchiderea unui
fisier de tip director se va realiza cu ajutorul apelului:
#include
<dirent.h>
int closedir (DIR *p);
Crearea unui nou director se face cu apelul:
#include
<sys/types.h>
int
mkdir (char *nume_dir, mode_t drepturi);
Se creeaza astfel un nou director avand numele specificat de primul
parametru si drepturile de acces specificate de cel de al doilea. Acest
director va contine doar doua legaturi si anume "." si
"..".
Stergerea unui
director se face cu ajutorul apelului:
#include <unistd.h>
int rmdir (char *nume_dir);
Acest apel reuseste doar daca directorul avand numele
specificat de parametru contine doar legaturile "." si "..".
Fisierele
de tip tub servesc la comunicarea unidirectionala intre procese, in
sensul ca descriptorii deschisi corespunzatori acestor
fisiere sunt fie in mod citire, fie in mod scriere. In
consecinta nu se pot deschide aceste fisiere in mod citire
si scriere simultan.
In plus, operatia de citire din
astfel de fisiere este distructiva, in sensul ca,
informatia odata citita dispare din fisier si, deci,
nu poate fi recuperata a doua oara din fisier.
Informatia este citita in mod fifo (primul intrat, primul
iesit), in sensul ca octetii sunt cititi in ordinea in care
au fost scrisi.
Orice tub are o capacitate finita. Mai
precis, daca se scrie informatie fara a fi citita, se
poate ajunge la umplerea tubului, caz in care procesul care scrie va fi blocat
la un apel write, pana cand un
alt proces va efectua un apel de citire, golind astfel tubul.
O caracteristica
esentiala a acestui tip de fisiere este numarul de
descriptori deschisi pentru citire, precum si numarul de
descriptori deschisi pentru scriere.
Fisierele de tip tub se impart
in doua categorii:
tuburi obisnuite (fara nume) ale
caror i-noduri nu se regasesc in
tabela de i-noduri de pe disc, ci numai in tabela de
i-noduri din memorie. Aceste tuburi nu sunt disponibile decat procesului care
le-a creat precum si descendentilor acestuia. Numarul de
legaturi fizice ale acestora este totdeauna nul si, in consecinta,
nu le corespund intrari in nici un director. Aceste fisiere dispar
odata cu terminarea oricarui proces ce are deschis un descriptor asupra
acestora.
tuburi numite, ce au cel putin o
legatura fizica intr-un director si a caror
existenta nu depinde de existenta unor procese particulare.
Aceste fisiere pot fi vizualizate cu ajutorul comenzii ls -l, in dreptul caracterului ce
desemneaza tipul de fisier putand fi observata litera p.
Tuburile obisnuite
Asa cum am spus mai sus,
descriptori asupra unui tub obisnuit nu pot avea decat procesul care l-a
creat precum si descendentii acestuia ce obtin descriptorii prin
mostenire sau prin apel la primitiva dup.
Crearea
unui tub obisnuit se face cu ajutorul primitivei:
#include <unistd.h>
int pipe (int *p
unde argumentul este parametru de iesire si
corespunde unui vector de minim doi intregi, alocat in prealabil. In caz
ca apelul a fost incununat de succes, p[0] va contine un descriptor in mod
citire, iar p[1] va contine un descriptor in scriere aferent noului
fisier creat. Spre deosebire de descriptorii deschisi pentru
fisiere de tip obisnuit, anumite operatii sunt ilegale asupra
acestora, cum ar fi lseek sau ioctl. In schimb, cu ajutorul apelului fcntl, se poate comanda ca
operatiunile de scriere sau citire sa devina neblocante. Implicit,
un urma crearii, descriptorii au proprietatea ca operatiunile de
citire sau scriere sa fie blocante
Citirea
din astfel de fisiere se face cu ajutorul primitivei read. Descriem in continuare comportarea acestei primitive la
citirea dintr-un tub obisnuit. Presupunem ca tubul contine dim caractere. Fie secventa de cod
:
#define DIM_BUF 128
.....
char buf[DIM_BUF];
int nr;
nr = read (p[0],
buf, DIM_BUF* sizeof(char));
Efectul acestui apel
este urmatorul:
daca tubul nu este gol (dim > 0) atunci se citesc min(dim, DIM_BUF)
caractere, iar acest numar reprezinta
numarul de caractere citite.
daca tubul este gol (dim
= 0) atunci:
a.
daca numarul de descriptori
deschisi in scriere este 0, atunci
codul de retur este 0, ceea ce este echivalent cu
sfarsitul fisierului
b.
daca numarul de descriptori
deschisi in scriere este diferit de 0,
atunci:
i.
Daca operatiunea de citire este blocanta atunci
procesul
asteapta ca sa se efectueze o
operatiune de scriere via un descriptor deschis in scriere.
ii.
Daca operatiunea de citire este neblocanta
codul de retur este -1, iar ERRNO ia valoarea EAGAIN,
daca este pozitionat
indicatorul O_NONBLOCK
codul de retur este 0, daca este pozitionat indicatorul
O_NDELAY
Remarcam
faptul ca manuirea defectuoasa a descriptorilor ce corespund unui tub poate sa
conduca la autoblocarea unui proces in situatia in care acesta face o
tentativa de citire blocanta dintr-un tub gol, ca in exemplul
urmator:
int p[2];
char ch;
pipe (p);
read (p[0], &ch, sizeof(char));
Apelul este blocant
deorece exista descriptorul deschis in scriere. Un alt exemplu este acela
in care doua procese se blocheaza unul pe celalalt:
int p1[2],
p2[2];
char
ch;
pipe (p1);
pipe (p2);
if (fork() == 0)
else
Pentru
a se evita situatii de genul celor descrise mai sus, drept o
masura de igiena programarii, se recomanda inchiderea
tuturor descriptorilor inutili.
Scrierea
in tuburile obisnuite se face cu ajutorul primitivei write. Fie secventa de cod:
#define DIM_BUF 128
.....
char buf[DIM_BUF];
.........
int nr;
nr = write (p[0],
buf, DIM_BUF* sizeof(char));
Efectul ultimului apel este urmatorul:
Inainte de toate scoatem in
evidenta faptul ca, pentru un tub obisnuit, daca s-au
inchis toti descriptorii de un fel, citire sau scriere, nu avem nici o
sansa sa recuperam descriptorul.
Daca
numarul de descriptori deschisi in citire este nul, procesul va primi
semnalul SIG_PIPE. Altfel:
daca scrierea este blocanta, se asteapta,
eventual, golirea tubului
pana cand toti octetii au fost
scrisi.
daca scrierea este neblocanta atunci:
a. daca este loc in tub
pentru a scrie toate caracterele, atunci
operatiunea
se efectueaza cu succes si codul de retur este DIM_BUF.
b. daca nu este loc in tub pentru a scrie
toate caracterele, atunci nu
se
scrie nici un caracter si
codul de retur este -1 iar ERRNO
ia valoarea EAGAIN,
daca este pozitionat
indicatorul O_NONBLOCK.
codul de retur este 0, daca este pozitionat
indicatorul
O_NDELAY.
In incheierea
acestui paragraf, exemplificam un model de implementare posibila, de
catre un program de tip SHELL a unei comenzi de tipul:
$ls -l | wc -l
Reamintim ca apelul dup duplica descriptorul dat drept argument in cel mai mic
descriptor liber.
int
p[2];
pipe (p);
if (fork() == 0)
else
Tuburile cu nume
Un fisier tub este "cu nume" daca are cel putin o legatura fizica (un nume)
intr-un director.
Crearea unui
asemenea fisier se poate face cu ajutorul comenzii SHELL:
$mkfifo [-p] [-n mod] nume..
unde prezenta
parametrului optional -p cere
crearea tuturor directoarelor care intervin, daca este necesar, iar
argumentul care urmeaza parametrului optional -n indica drepturile de acces asupra fisierului nou
creat, exceptand pe cele implicite ( a se vedea comanda umask). Din program, un asemenea fisier se poate crea cu
ajutorul apelului:
#include <sys/types.h>
#include
<sys/stat.h>
int mkfifo (char *nume, mode_t
mod);
unde primul argument
reprezinta numele fisierului de tip tub nou creat, iar al doilea
argument drepturile de acces exprimate prin disjunctie bit cu bit intre
constantele enumerate la prezentarea apelului stat.
Deschiderea unui fisier de
tip tub "cu nume" se face cu ajutorul primitivei open. In lipsa optiunilor O_NONBLOCK
sau O_NDELAY, aceste apeluri
sunt blocante in sensul ca o deschidere in citire asteapta ca
numarul descriptorilor deschisi in scriere sa fie nenul si
viceversa. Acest lucru reprezinta o modalitate de sincronizare a doua
procese. In cazul pozitionarii unuia din indicatorii O_NONBLOCK sau O_NDELAY care fac apelul de deschidere neblocant, atunci:
deschiderea in scriere reuseste
totdeauna.
deschiderea in citire esueaza (cod
de retur -1) daca nu exista nici un
descriptor deschis
pentru scriere.
Ca la orice fisier, tuburile
"cu nume" dispar daca numarul de legaturi fizice devine nul
si nici un proces nu poseda un descriptor asupra lui. Facem
observatia ca, atunci cand numarul de legaturi fizice
devine nul, dar exista inca descriptori deschisi asupra lui,
fisierul devine "tub obisnuit".
Operatiile
de citire si, respectiv, scriere se realizeaza cu ajutorul
primitivelor read si,
respectiv, write. Atragem
atentia asupra faptului ca atunci cand un fisier de tip tub
dispare (are zero legaturi fizice si nici un proces nu poseda un
descriptor deschis asupra lui) informatia necitita se pierde.


